Fun With Diffusion Models
Sampling from DeepFloyd IF (CFG, SDEdit, inpainting, visual anagrams), then training a time- and class-conditioned U-Net from scratch on MNIST to learn the diffusion process end-to-end.
Diffusion models learn to denoise; denoising, run in reverse, generates new images from pure noise. This project covers them in two halves: using DeepFloyd IF (a pretrained 4B-parameter model) to build CFG sampling, SDEdit, inpainting, and visual anagram pipelines; then training a small U-Net from scratch on MNIST to understand what diffusion actually is at the training-loop level.
The Forward Process
The forward process gradually destroys an image by adding Gaussian noise over steps. Each step follows:
where is a fixed noise schedule (linear or cosine). The key identity, the reparameterization, lets us jump directly to any timestep without stepping through all previous ones:
where . At , and is clean. At , and is pure noise.
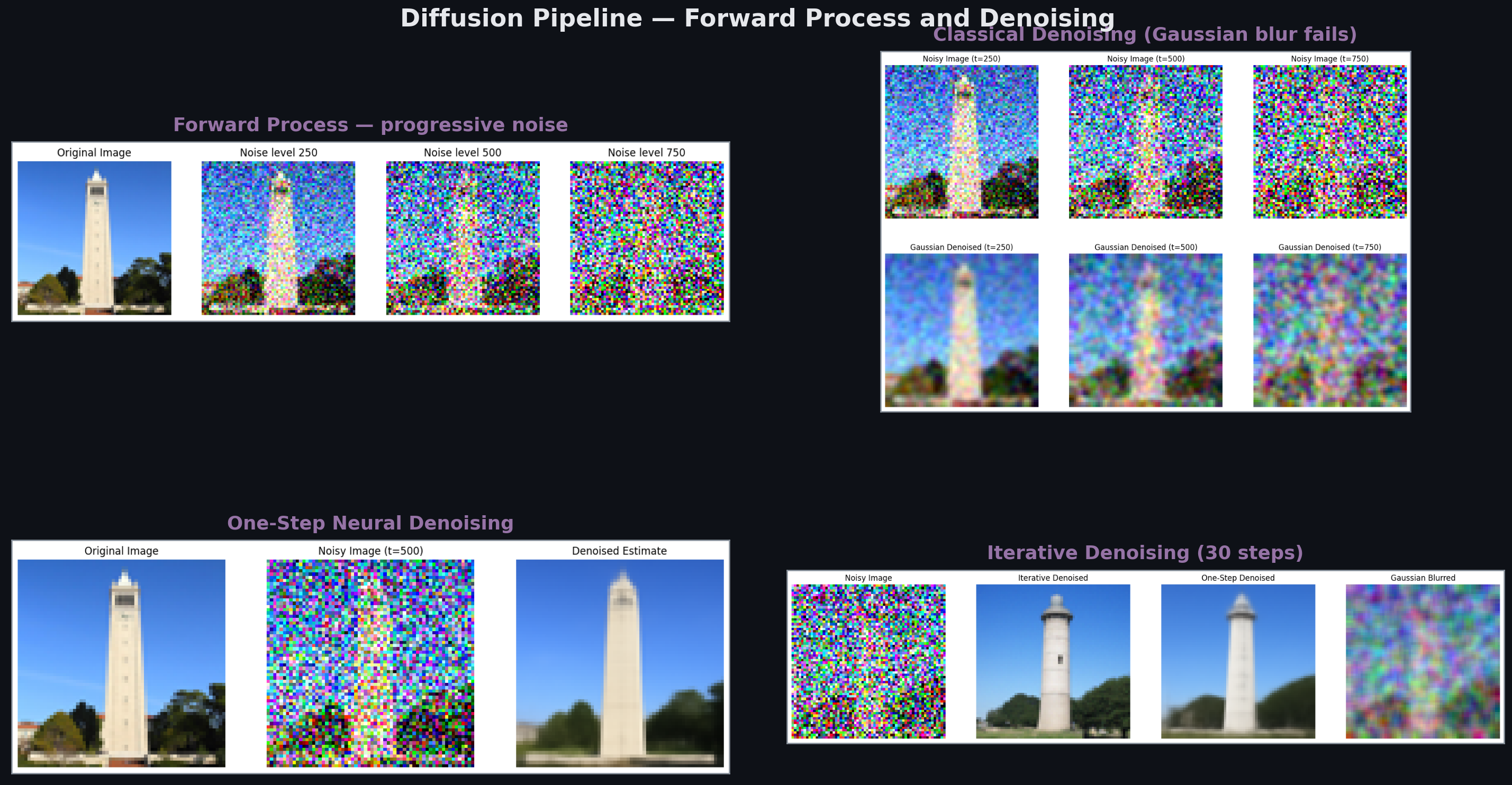
Classical denoising (Gaussian blur) fails: it smooths noise but also destroys all signal. A single forward pass of the trained U-Net does better (it predicts and subtracts it), but one-step denoising from still produces blurry results. The full iterative process (30 steps: denoise, add a small amount of noise back, denoise again) recovers sharp images because each step only asks the network for a small correction, keeping its predictions in-distribution.
Classifier-Free Guidance
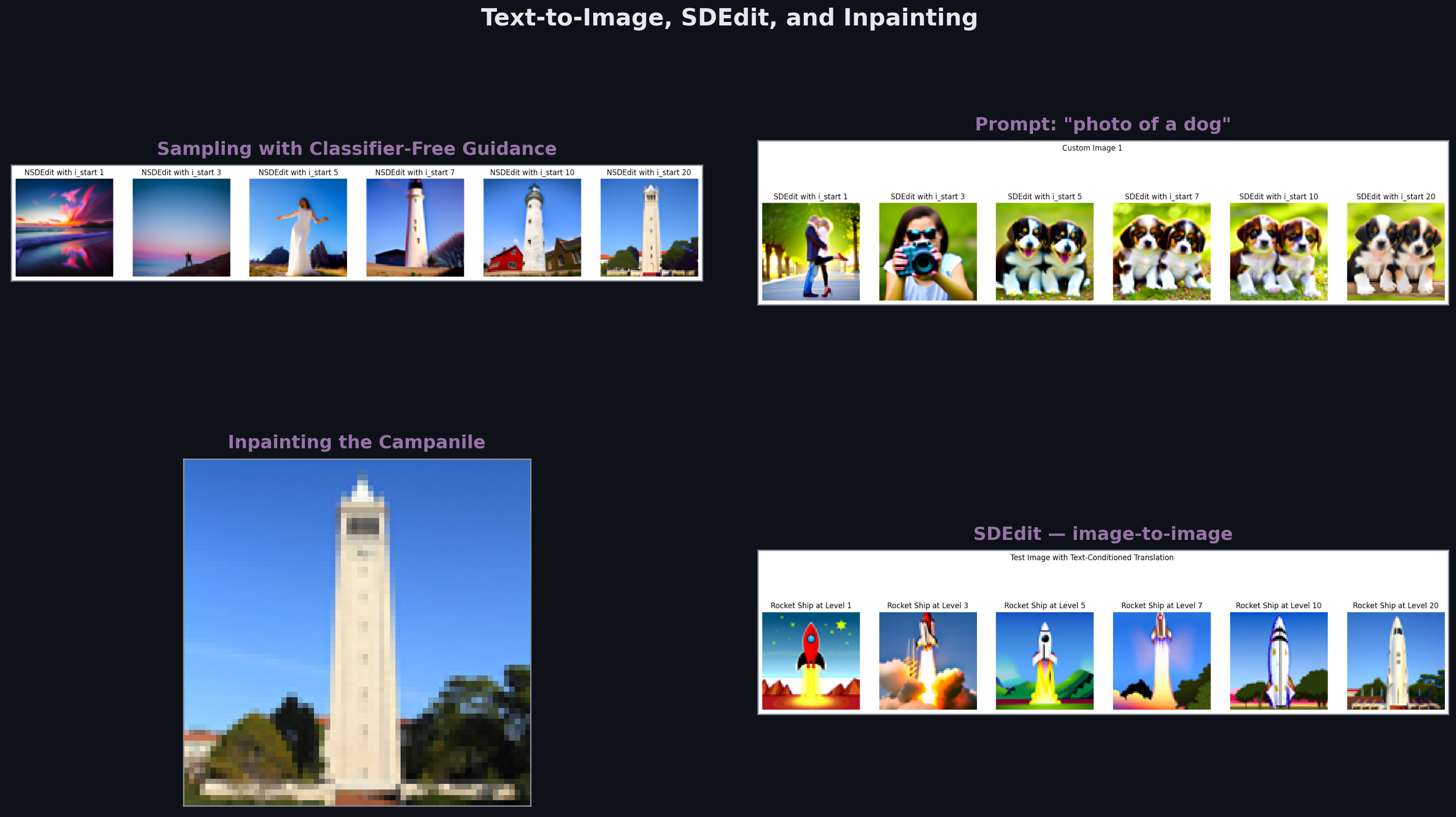
The standard DDPM sampling loop produces diverse but often prompt-misaligned outputs. Classifier-free guidance (CFG) trades diversity for prompt fidelity without a separate classifier. At each denoising step, run the U-Net twice (once conditioned on the text prompt, once unconditioned) and extrapolate:
The guidance scale controls the trade-off: is standard sampling; pushes strongly toward the conditional. The model is simultaneously trained on conditioned and unconditioned inputs (by randomly dropping the conditioning during training), which is why a single model handles both roles.
SDEdit and Inpainting
SDEdit: add noise to an existing image up to some timestep , then denoise with a new prompt. The amount of noise added controls the edit strength: small makes minimal changes (preserves structure), large allows major transformations (loses structure). The result inherits the original image’s low-frequency layout while adapting content to the prompt.
Inpainting (RePaint): at each denoising step, keep the known region by renoising it to match the current timestep, then splice it onto the generated region before the next step:
This forces the known region to stay on-distribution for timestep , while letting the model generate coherent content inside the mask that blends with its context.
Visual Anagrams
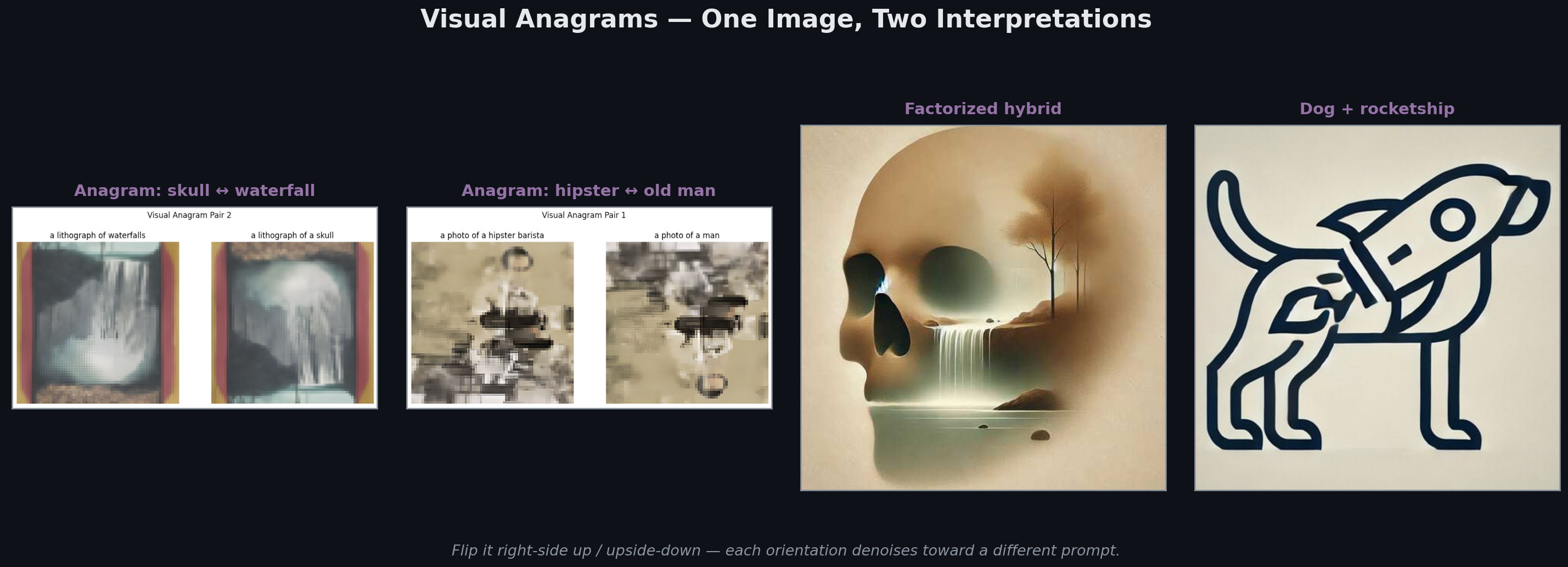
One image, two prompts, depending on orientation. At each denoising step, predict noise for the upright image under prompt A and for the flipped image under prompt B, then average:
Averaging noise predictions averages the score function gradients; the generator simultaneously follows the gradient toward “skull” and the gradient toward “waterfall upside-down.” Because the two gradients point in compatible directions (the image has to satisfy both constraints), the denoising process finds a composition that works for both views.
Training a U-Net From Scratch

Part B builds diffusion from first principles on MNIST. The U-Net takes a noisy image and timestep (encoded as a sinusoidal embedding) and predicts the noise . The training objective is simple MSE on the noise prediction:
Each training step: sample , sample , sample , compute via the reparameterization, predict noise, backprop. The model never sees a clean image during the forward pass, only noisy ones at random timesteps.
By epoch 5 the network learns digit structure but samples are noisy. By epoch 20 it produces clean, diverse digits. Adding class conditioning (embedding the digit label alongside the timestep) lets it generate specific digits on demand; the bottom-right panel shows one of each 0–9.
DeepFloyd IF uses the same loss, the same architecture family (encoder-bottleneck-decoder with skip connections), and the same sampling loop, just scaled up by ~6 orders of magnitude in parameters and trained on a much larger dataset with text conditioning. The MNIST version is a complete, working proof-of-concept of the same mechanism.
Related projects

Neural Radiance Fields (NeRF)
Training an MLP to represent a 3D scene as a continuous function from (x, y, z, θ, φ) to (RGB, density). Volume rendering turns the field back into images; the field itself is the 3D model.

Auto-Stitching Photo Mosaics
Building a panorama pipeline from scratch: Harris corner detection, Adaptive Non-Maximal Suppression, feature matching, RANSAC for homography estimation, and Laplacian-pyramid blending.

Face Morphing with Delaunay Triangulation
Smooth warping between two faces via point correspondences, Delaunay triangulation, and affine warps per triangle. Plus: population mean faces and caricature generation by extrapolation.