17× Faster 2D Convolution: AVX2 + OpenMP
Hand-optimized SIMD kernels with parallel tiling achieve 17× speedup over naive implementation. Deep dive into vectorization, memory patterns, and performance engineering.
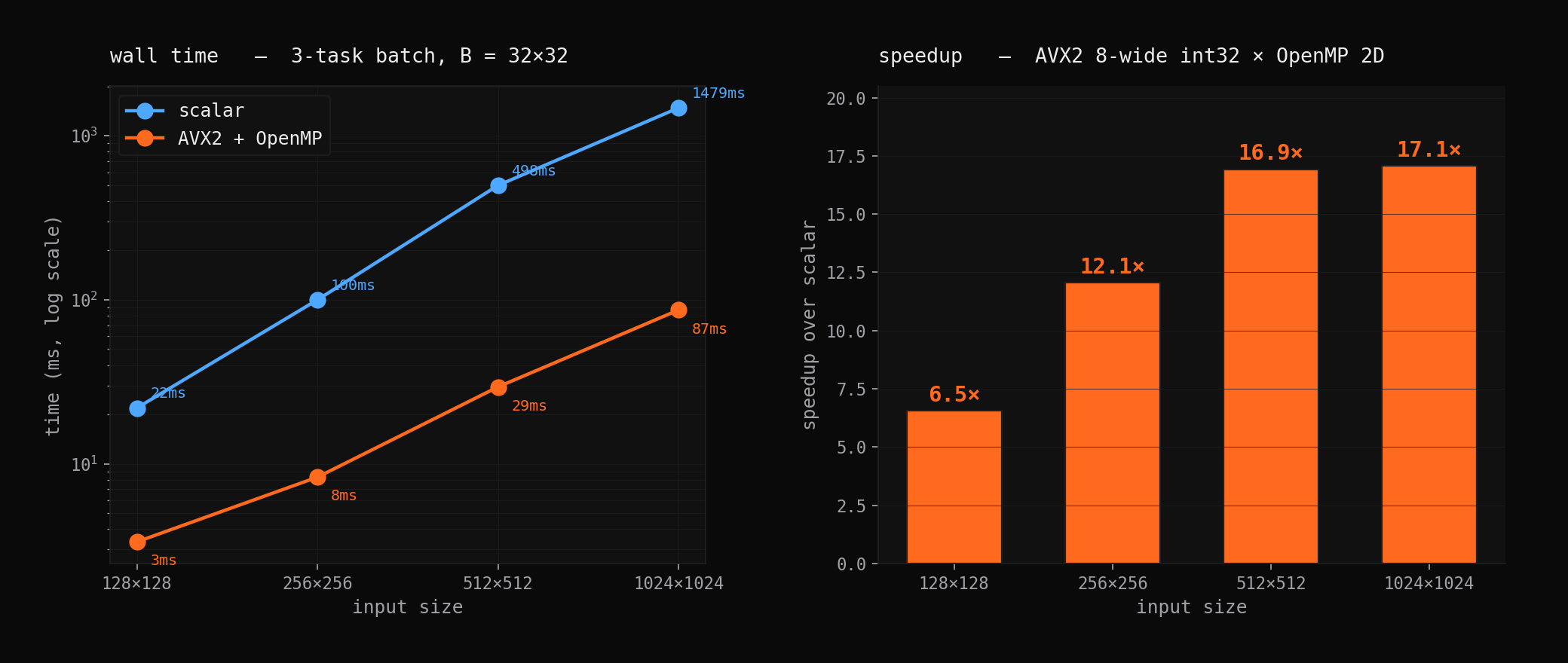
Naive 2D convolution is O(H × W × Kh × Kw) with poor cache behavior: every output pixel re-reads overlapping input windows, and the scalar inner loop uses none of the CPU’s 256-bit vector units. Starting from a perf stat baseline showing 85% cache miss rate and <5% vector utilization, three optimization layers brought 1024×1024 throughput from 1479 ms to 87 ms.
SIMD Vectorization
AVX2 provides 256-bit vector registers. For int32 convolution, that means 8 pixels processed per multiply-accumulate instruction instead of 1:
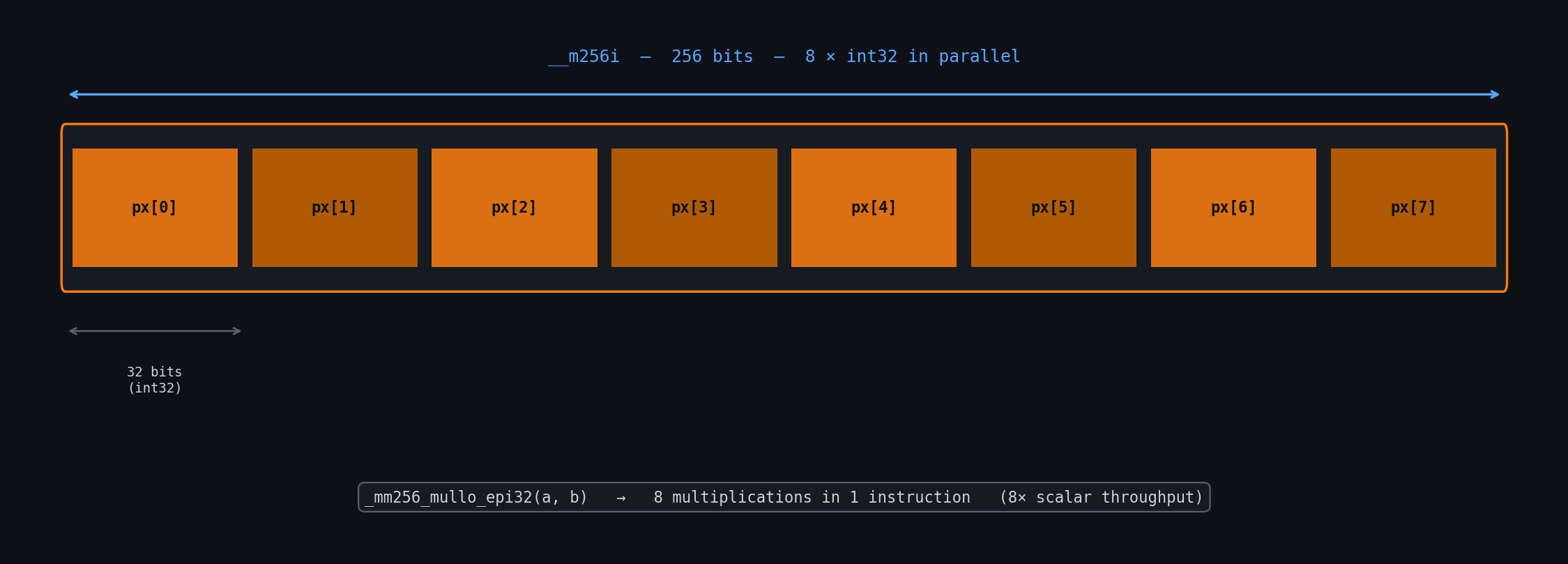
The inner loop loads 8 pixels from the input window into __m256i, multiplies by the broadcast kernel weight, and accumulates. Horizontal reduction (summing the 8 lanes to a scalar) adds ~6 cycles per output pixel but enables 8× arithmetic throughput.
__m256i pixels = _mm256_loadu_si256((__m256i*)&input[row][col]);
__m256i kernel_val = _mm256_set1_epi32(kernel[kr][kc]);
__m256i products = _mm256_mullo_epi32(pixels, kernel_val);
acc = _mm256_add_epi32(acc, products);Image widths that aren’t multiples of 8 require a scalar cleanup loop for the remainder. This could be eliminated with masked loads, but the complexity isn’t worth it for typical image sizes.
Cache-Friendly Tiling
Processing the full image row by row causes repeated cold cache misses on the kernel weights. 64×64 output tiles bring the working set (input patch + kernel + output tile) under 32 KB, fitting in L1 cache. Each tile is processed to completion before moving to the next, giving good temporal locality.
OpenMP parallelizes across tiles with collapse(2):
#pragma omp parallel for collapse(2) schedule(dynamic)
for (int ti = 0; ti < n_tiles_y; ti++) {
for (int tj = 0; tj < n_tiles_x; tj++) {
process_tile(ti, tj);
}
}collapse(2) creates one work unit per tile rather than per row, typically 256+ independent tasks on a 1024×1024 image, enough for dynamic scheduling to load-balance the edge tiles cleanly.
Speedup by Stage
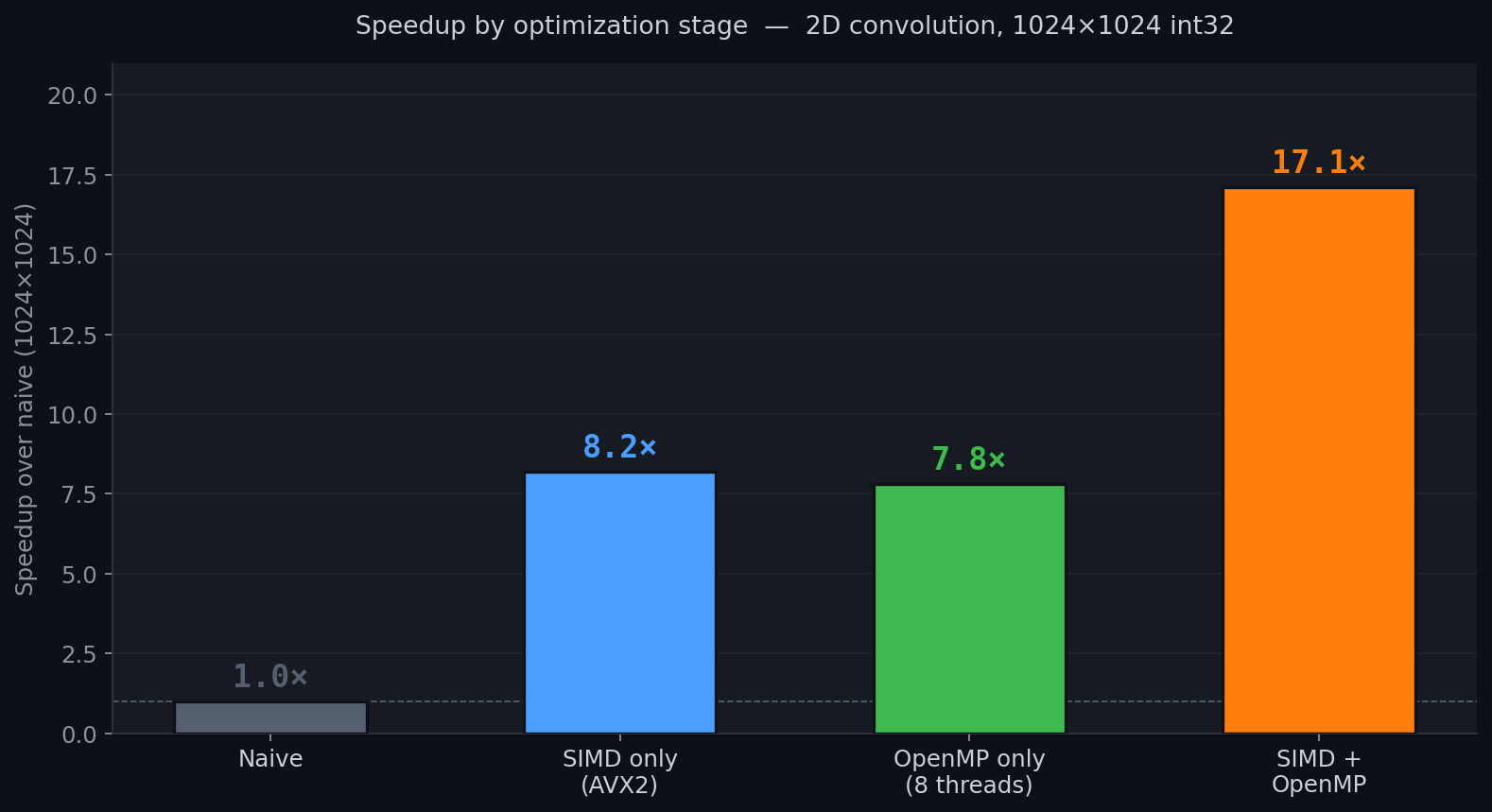
SIMD alone gives 8.2×, slightly above the theoretical 8× because pre-flipping the kernel (a 180° rotation done once at init rather than per-output-pixel) eliminates index arithmetic from the inner loop. OpenMP alone gives 7.8× on 8 cores, near-linear, confirming the workload is embarrassingly parallel. Combined, they give 17.1× rather than the 65.6× theoretical product, because at high thread counts the bottleneck shifts from compute to memory bandwidth.
Input/Output

Testing on synthetic ring + noise input with a 5×5 edge-detection kernel and a 9×9 box blur. Results are bit-exact against the naive reference across all tested sizes and kernel shapes, verified with address sanitizer builds.
Profiling Notes
Two “obvious” optimizations that made no difference:
- Manual prefetching (
__builtin_prefetch): hardware prefetchers already handle the regular access pattern. - 4× loop unrolling: GCC’s auto-unroll at -O2 was already doing it; explicit unrolling added 3% for 3×3 kernels and nothing for larger ones.
The lesson: trust perf stat over intuition. IPC actually dropped after optimization (fewer, more complex SIMD instructions), but total throughput was the metric that mattered.
Related projects
MNIST Neural Network in Pure RISC-V Assembly
A complete 2-layer MLP for digit classification: matrix multiply, ReLU, argmax, file I/O, and all infrastructure, written entirely in hand-coded RISC-V assembly without any library calls.

Build Your Own World
Procedurally generated tile-based dungeons with Dijkstra-routed hallways, circular line-of-sight, and deterministic save/load via seed replay. Written in Java from scratch.