MNIST Neural Network in Pure RISC-V Assembly
A complete 2-layer MLP for digit classification: matrix multiply, ReLU, argmax, file I/O, and all infrastructure, written entirely in hand-coded RISC-V assembly without any library calls.
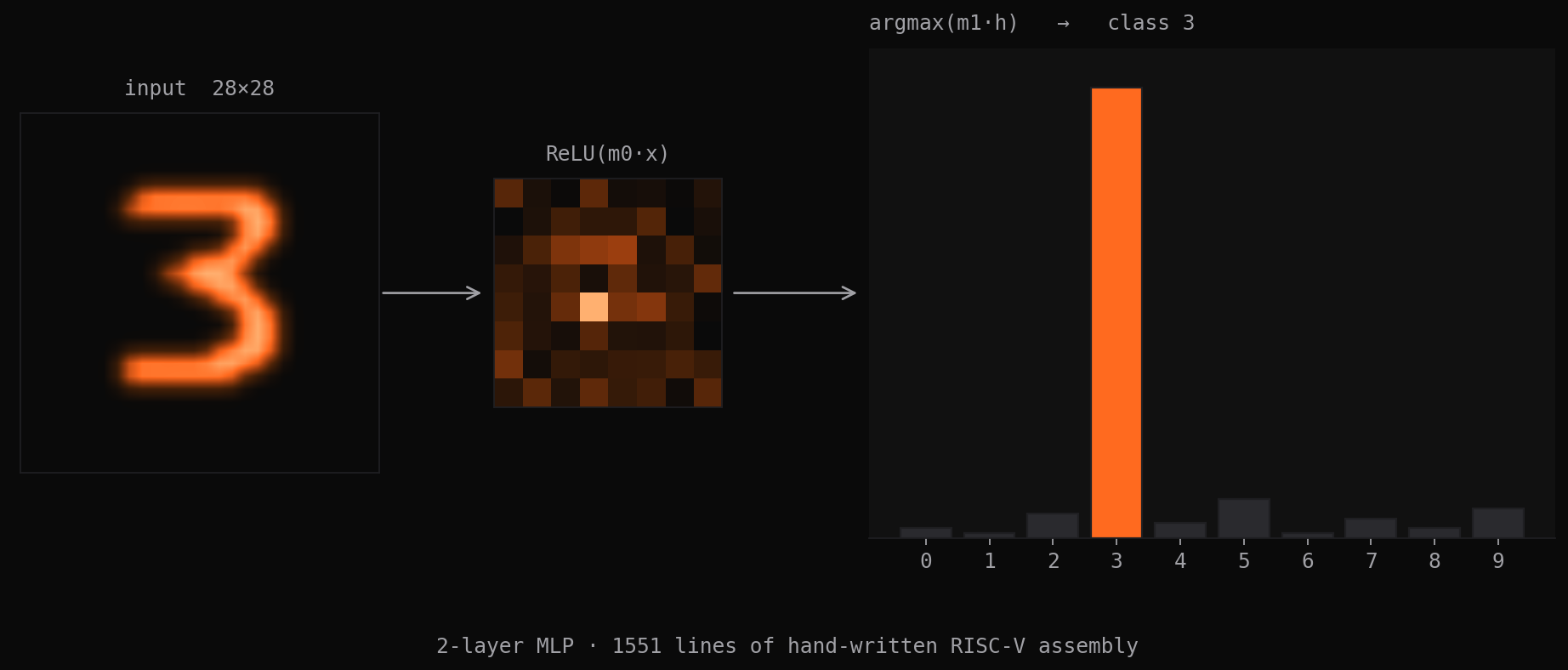
No standard library, no compiler, no floating-point hardware. A complete neural network inference pipeline in 1551 lines of RISC-V assembly: matrix multiply, ReLU, argmax, binary file I/O, a bump allocator, and the calling convention wiring to hold it all together.
Network Architecture
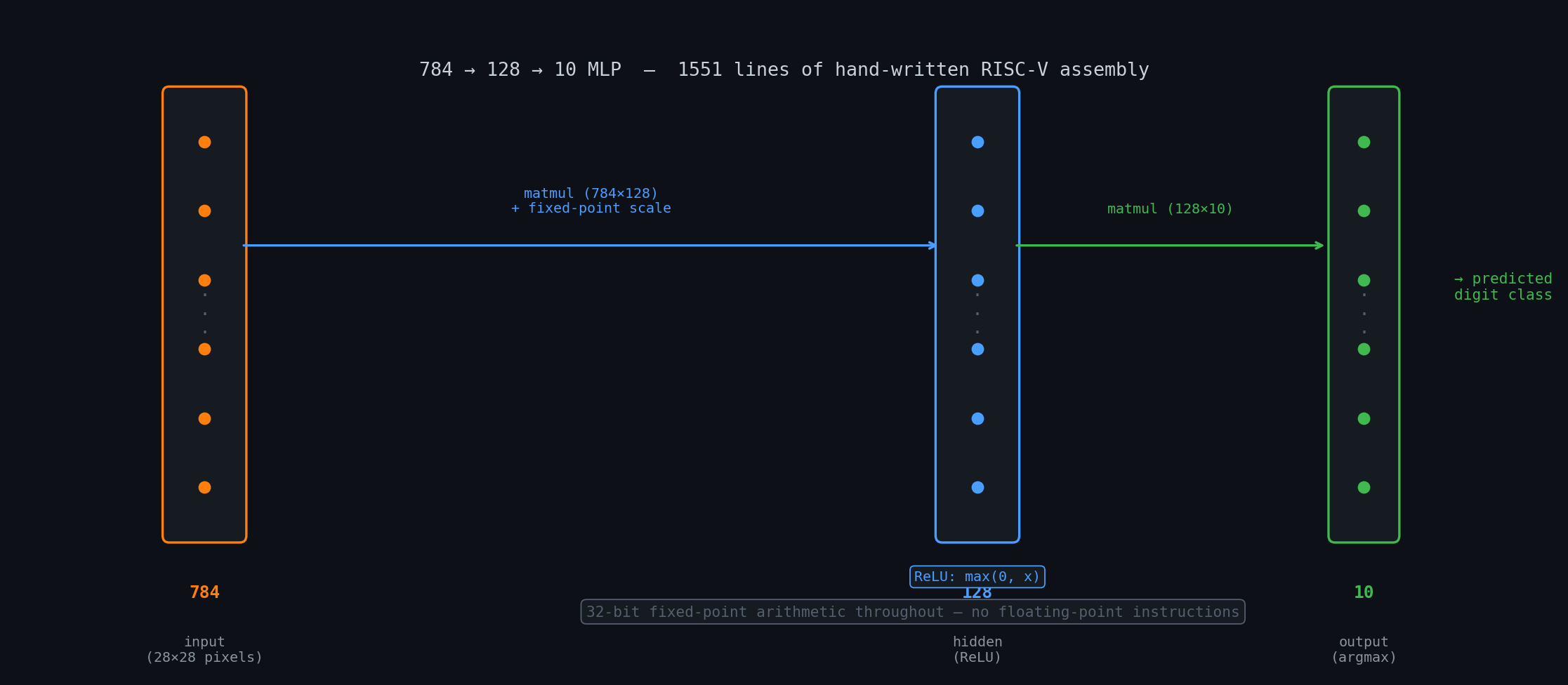
The forward pass is two matrix multiplications separated by a ReLU:
where , , and all arithmetic is 32-bit fixed-point. Weights are pre-scaled during Python training so that the assembly only needs integer multiply-and-shift, with no floating-point instructions anywhere in the binary.
Fixed-point multiplication: multiply two integers, then arithmetic-right-shift by 16 to recover the fractional result:
mul t0, a0, a1 # 64-bit product in t0 (sign-extended)
srai a0, t0, 16 # scale back — preserves signMatrix Multiply
The core kernel is a triple-nested loop over output rows, output columns, and the inner dimension. Row-major storage means the inner loop over the inner dimension is a sequential load, giving good spatial locality. The inner loop is unrolled 4× to reduce branch overhead.
Address arithmetic uses shift rather than multiply throughout:
slli t0, t1, 2 # byte offset = col * 4 (cheaper than mul)
add t0, a0, t0 # pointer into row
lw t2, 0(t0) # load elementAt 784×128 elements for the first layer, the forward pass does ~100K fixed-point multiply-accumulates. Venus cycle counts show matmul consuming 85% of total execution time.
ReLU and Argmax
ReLU is a branch per element:
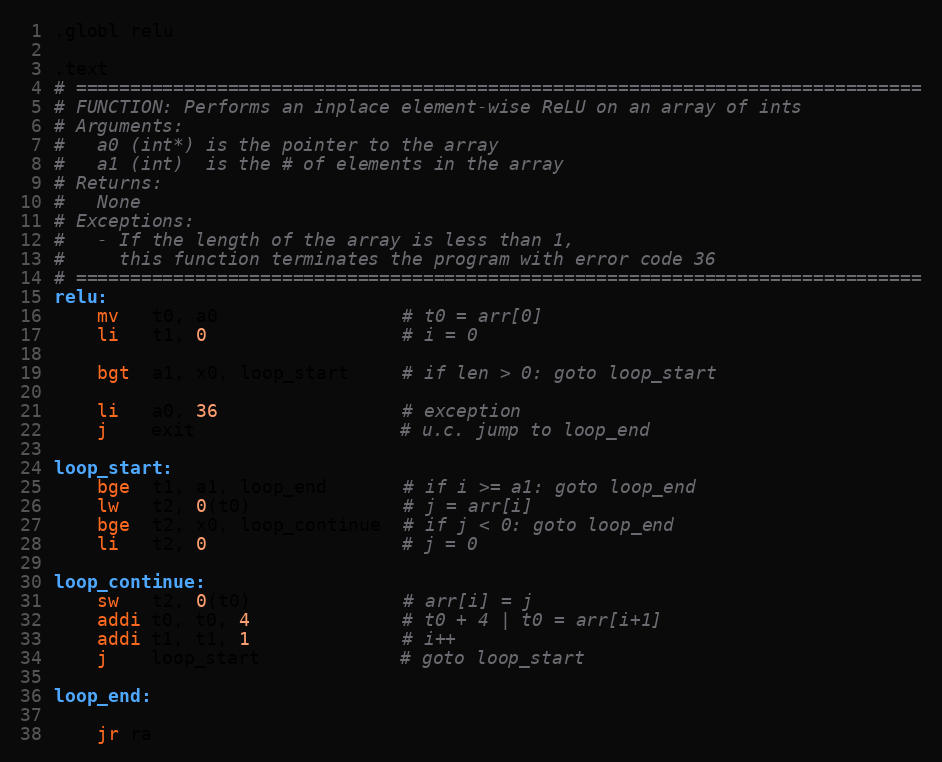
The implementation loads each element, branches if already ≥ 0 (no write needed), otherwise writes 0. Pointer arithmetic advances by 4 bytes per element. A modern RISC-V vector extension could replace the loop with a single masked operation, but Venus doesn’t support RVV.
Argmax walks the output array keeping a running max value and max index in registers: no memory allocation, O(n) with minimal register pressure.
File I/O and Memory
Matrix weights are read from binary files using Venus ECALL system calls: open (1024), read (63), close (57). The code reads the 8-byte header (rows, cols) first, then allocates the right amount of heap space, then reads the data.
The allocator is a 3-instruction bump pointer:
lw t2, 0(t1) # current heap_ptr
add t3, t2, t0 # new heap_ptr = old + bytes
sw t3, 0(t1) # update heap_ptr
mv a0, t2 # return old pointerNo free: inference only ever allocates, never releases. Heap overflow is checked explicitly before each allocation.
Results
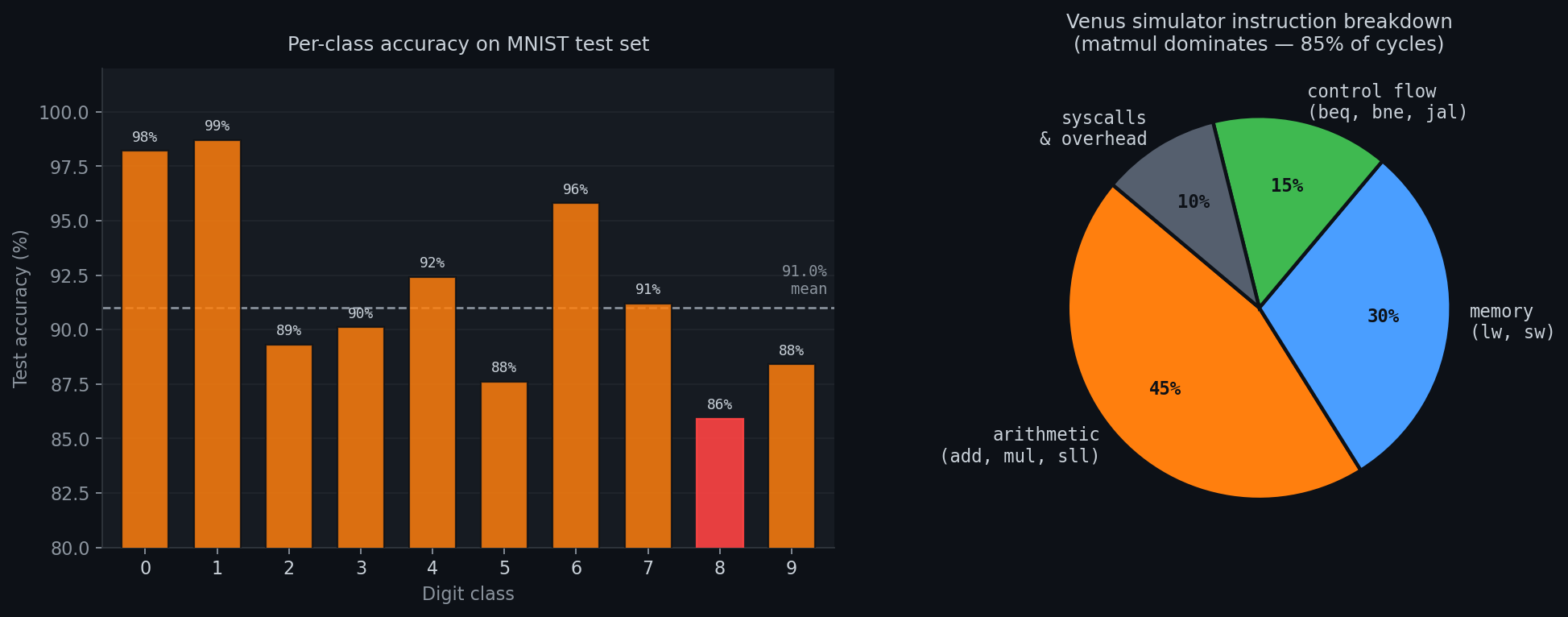
91% overall accuracy on the MNIST test set. Digit 8 is the hardest (86%); it shares structural features with 3, 5, and 9. Digits 0 and 1 are easiest (>98%) because their shapes are geometrically distinct.
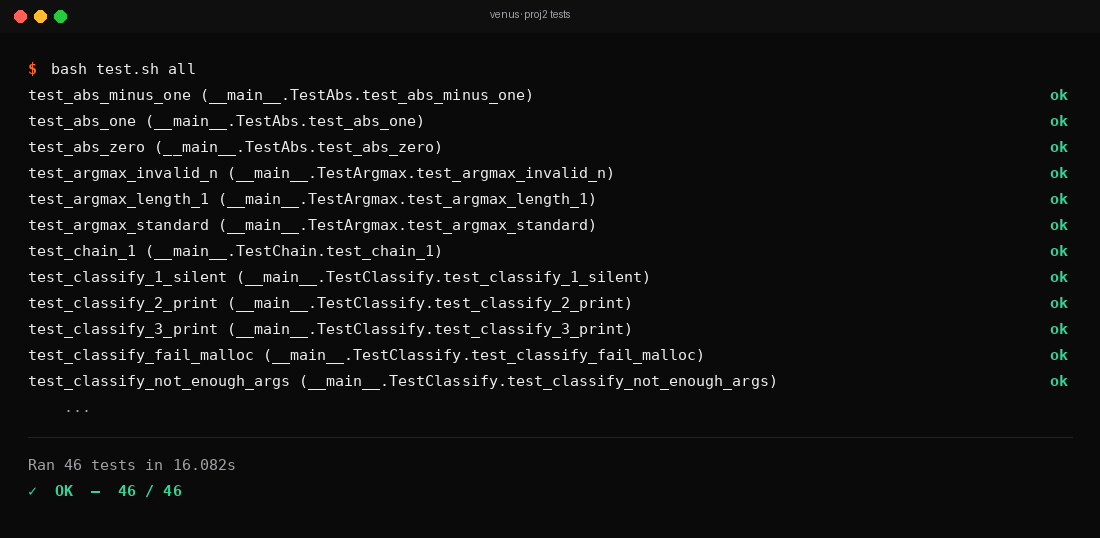
Each kernel (abs, argmax, dot, matmul, relu, read_matrix, write_matrix) has independent unit tests with hand-computed expected outputs. All 46 tests pass, including error-code paths for invalid inputs, heap overflow, and file-not-found.
What Writing Assembly Teaches
The main thing assembly forces: you cannot hide from the calling convention. Every function needs a prologue (push ra, s0–sN), every early exit needs the matching epilogue, and any mistake silently corrupts the return address. A high-level language handles this automatically. Writing it by hand for 1551 lines gives a visceral sense of what compilers do and why calling conventions exist.
The fixed-point decision was also instructive. The Venus simulator doesn’t model FPU instructions accurately, and the assignment spec required integer arithmetic. Pre-scaling weights in Python to fit the fixed-point range took about 10 lines of NumPy; the assembly itself never sees a float. The accuracy cost (91% vs ~97% for a float implementation) is entirely from quantization.
Related projects
17× Faster 2D Convolution: AVX2 + OpenMP
Hand-optimized SIMD kernels with parallel tiling achieve 17× speedup over naive implementation. Deep dive into vectorization, memory patterns, and performance engineering.

Build Your Own World
Procedurally generated tile-based dungeons with Dijkstra-routed hallways, circular line-of-sight, and deterministic save/load via seed replay. Written in Java from scratch.
32-bit RISC-V CPU from Logic Gates
A complete 2-stage pipelined RV32I processor built from first principles in Logisim: ALU, register file, control unit, and memory system, all hand-wired from basic gates.