Entropy Wordle Solver
Information-theoretic greedy solver that picks each guess to maximize expected entropy over the remaining word set, averaging 3.92 guesses across 300+ games.

The Challenge: Wordle gives you 6 attempts to guess a 5-letter word from 2,315 possibilities. Each guess reveals color patterns: green for correct position, yellow for wrong position, gray for absent. How do you choose guesses to minimize expected attempts?
The Insight: This is fundamentally an information extraction problem. Each guess partitions the remaining word space based on possible responses. The optimal strategy maximizes information gained per guess, which means maximizing the entropy of the pattern distribution.
Information Theory Foundation
The key insight: minimizing expected remaining uncertainty is equivalent to maximizing information gain, which equals the entropy of the pattern distribution.
Model the secret word as uniform over 2,315 possibilities. At time step , after observing patterns , the posterior remains uniform over the surviving words because patterns act as hard filters; they eliminate words but don’t shift relative probabilities among survivors.
For candidate guess , let be the resulting pattern. Because knowing makes deterministic:
So minimizing (leftover uncertainty) is equivalent to maximizing (pattern entropy). Given current alphabet and guess :
High entropy means many equally-sized partitions, giving maximum elimination power. The opening word SOARE achieves bits against 2,315 words, creating 168 distinct patterns with relatively flat distribution. Compare:
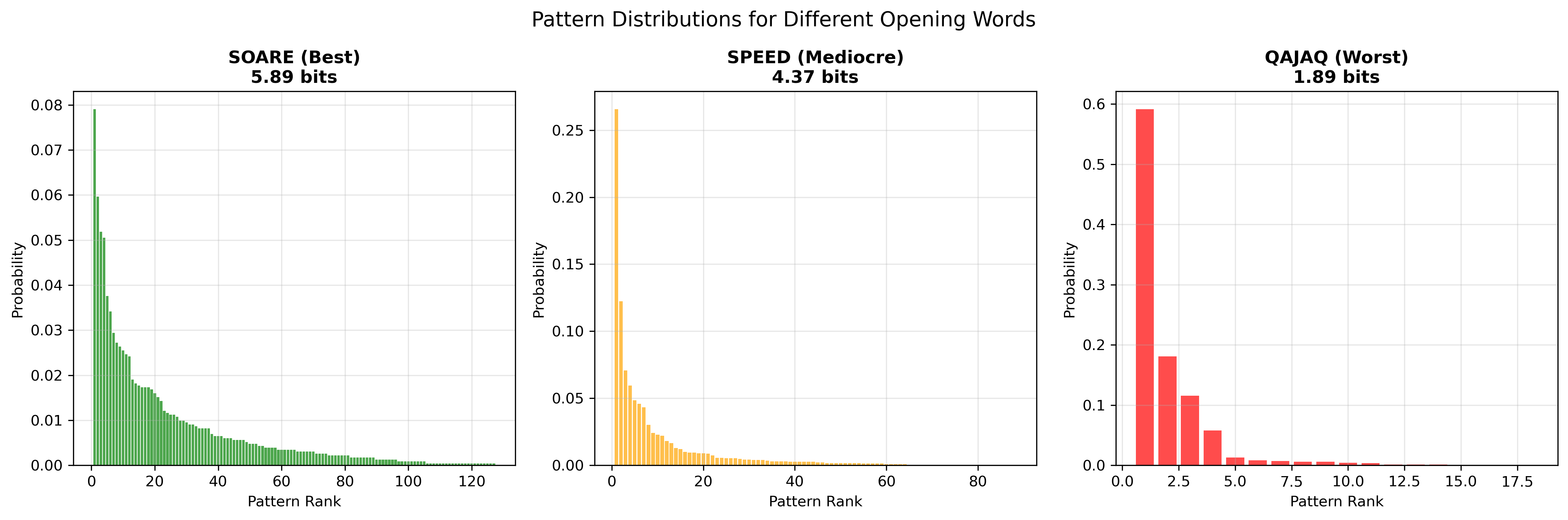
QAJAQ’s distribution (right panel) collapses to 12 patterns; 60% of the time it gives exactly the same response, so most of its “guess budget” is wasted.
Pattern Distribution Analysis
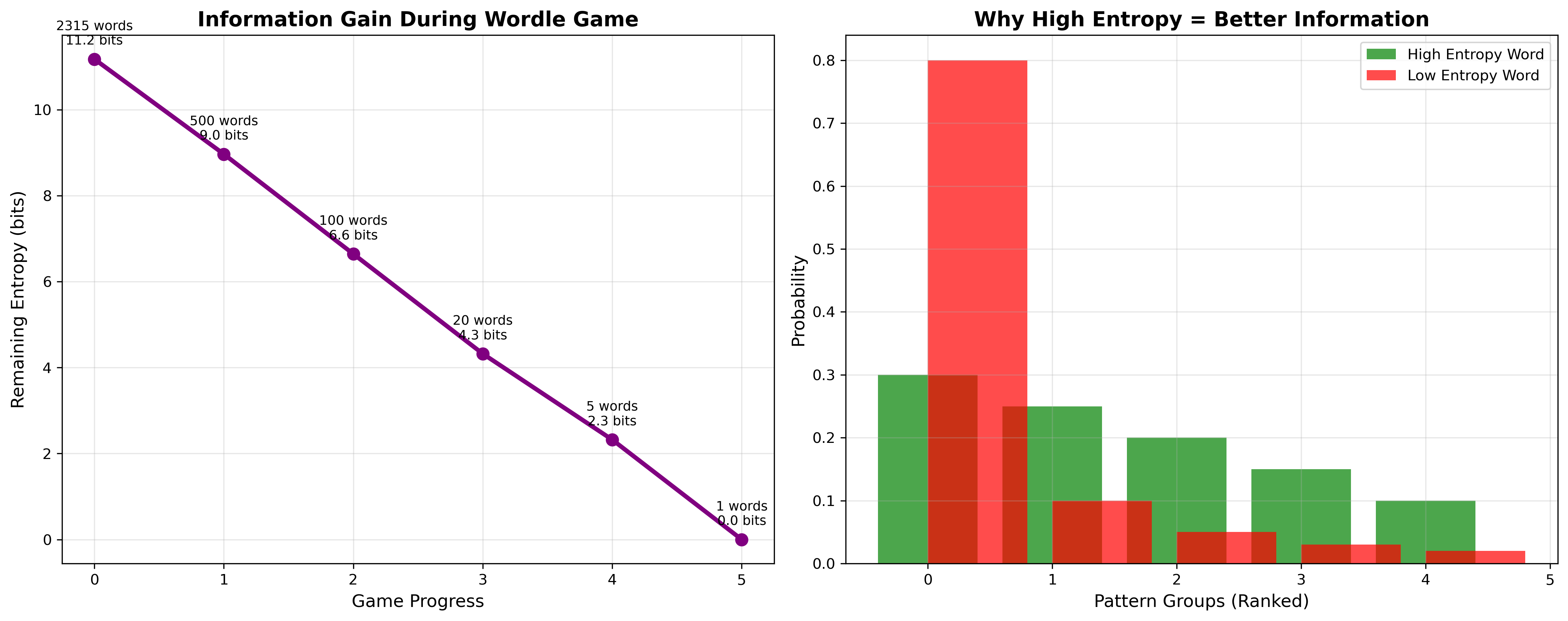
The left panel shows how remaining uncertainty drops from bits at the start to 0 at the solution. Each optimal guess extracts roughly 2–3 bits. The right panel contrasts a high-entropy word (green bars, spread across many pattern groups) against a low-entropy word (red bars, most probability mass in a single large group). Choosing the high-entropy word always reduces the next turn’s search space more.
Algorithm Implementation
The solver implements a greedy optimization at each step:
def find_best_guess(alphabet, allowed_guesses):
best_guess, max_entropy = None, 0
for guess in allowed_guesses:
pattern_groups = divide_alphabet(guess, alphabet)
H = entropy(prob_dist(pattern_groups))
if H > max_entropy:
max_entropy, best_guess = H, guess
return best_guessComputational cost: evaluating every candidate against every remaining word is O(|guesses| × |words|) per turn, up to 12k × 2k = 24M pattern lookups. The main optimization is precomputing the full pattern table offline (5 min, ~300MB), reducing each in-game lookup to a dictionary read.
One non-obvious correctness requirement: the pattern computation must handle repeated letters with the right priority. Green (exact match) always takes precedence. Among yellow matches, earlier positions in the guess win, and each letter in the answer can only be claimed once:
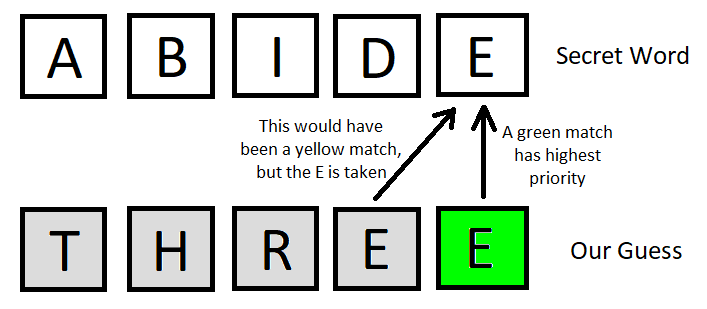
Guessing THREE against ABIDE returns (0,0,0,0,2) and not (0,0,0,1,2) because the green E at position 5 consumes the only E in the answer, so position 4 gets no yellow match. This priority rule must be exact; a wrong implementation produces subtly wrong remaining-alphabet filtering that compounds across turns.
Advanced Optimizations
Opening book: the first guess is always computed against the full 2,315-word set. Since this is constant, precompute it once. SOARE is optimal by 0.02 bits over CRANE and 0.02 bits over SLATE.
Endgame strategy switch: when ≤3 words remain, entropy maximization is wrong. Guessing a non-answer like CAMEL perfectly disambiguates two candidates (price/pride) but costs a turn even after you know the answer. Instead, limit candidates to the remaining alphabet; each guess has a nonzero chance of immediately winning, giving expected 1.5 guesses vs 2.
Warm cache: the precomputed pattern table (pattern_table[guess][answer]) reduces each pattern evaluation from character-level computation to O(1) lookup. This is the dominant speedup; early game calls evaluate ~12k × 2k entries, so the table turns 24M string ops into 24M dict lookups.
Performance Analysis
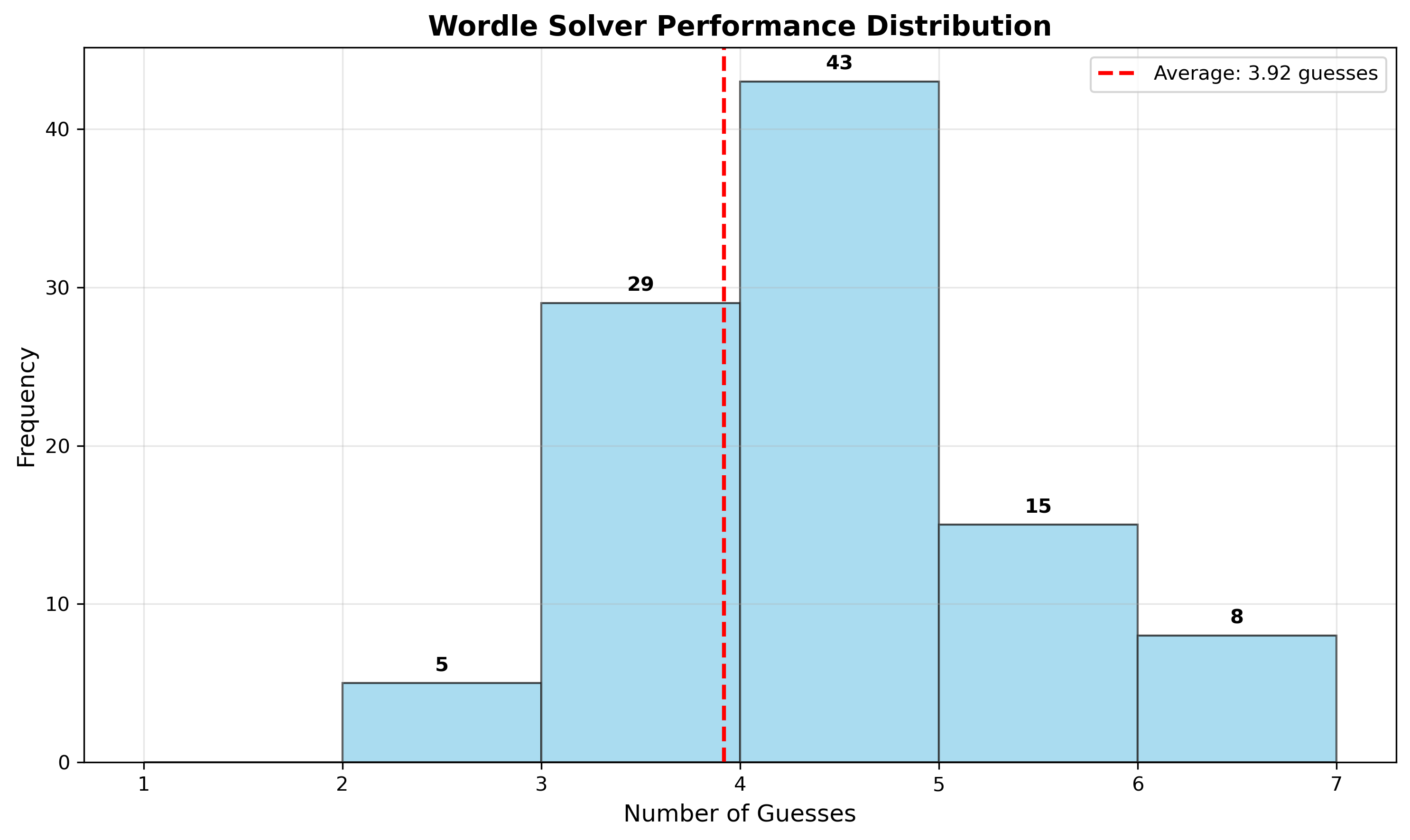
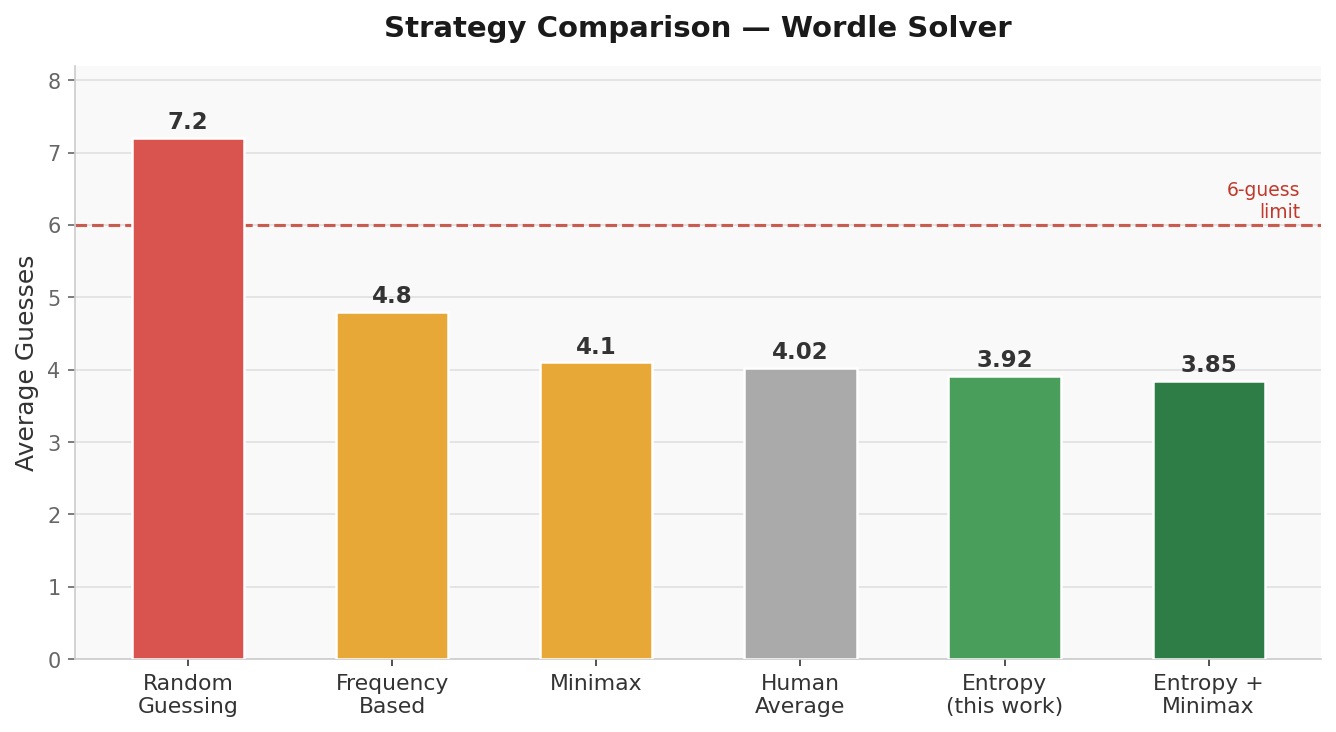
Over 300 sampled games: 85% solved in ≤4 guesses, 8 required 6. The few near-failures involve word families with overlapping patterns; BATCH/WATCH/MATCH all produce similar feedback against typical openers, forcing late disambiguation.
The strategy comparison (right) shows why entropy outperforms alternatives. Frequency-based (pick words with common letters) misses the joint distribution: a word like ESSES has common letters but almost no partitioning power. Minimax (minimize worst case) is conservative; it avoids bad luck at the cost of average performance. Entropy directly optimizes the quantity that drives average guesses down.
Failure mode analysis: the 6-guess cases share a pattern, a “word cluster” where 4–5 words share positions 2–5 (e.g., WATCH/BATCH/MATCH/LATCH). After eliminating one per turn, 3 guesses can be exhausted on correct-but-not-winner guesses before the right one surfaces. The endgame switch helps but doesn’t fully solve clusters of size >3.
Extensions
This framework generalizes to any sequential information-gathering problem where you choose observations to minimize remaining uncertainty:
- 20 Questions: pick the binary question that most evenly splits remaining hypotheses, exactly entropy maximization with binary
- Active learning: select labeled examples to maximize information gain about model parameters
- Adaptive testing: choose diagnostic tests to minimize expected number of tests to reach a diagnosis
A natural extension is look-ahead search: instead of maximizing at step , maximize the expected information gain over two steps. This doubles the computation (evaluate all pairs of guesses) but converges closer to the true optimal policy. Empirically this would push average guesses from 3.92 toward ~3.5, trading runtime for performance.
Related projects

MCMC Cipher Decoder
Metropolis-Hastings breaking substitution ciphers against bigram frequencies. Watch garbled text slowly resolve into English over MCMC iterations.
Deep Learning from Scratch
The full arc: backpropagation in raw NumPy, CNNs with BatchNorm and Dropout trained to 78% on CIFAR-10, multi-head self-attention for text summarization, and a Masked Autoencoder that reconstructs images from 25% of their patches, then transfers those features to downstream tasks.
Classical ML from Scratch
Two learning paradigms built from NumPy up: tree-based spam classification (decision tree, Random Forest, AdaBoost) and SVD/ALS matrix factorization for movie recommendations. No frameworks; matched scikit-learn on both.