Classical ML from Scratch
Two learning paradigms built from NumPy up: tree-based spam classification (decision tree, Random Forest, AdaBoost) and SVD/ALS matrix factorization for movie recommendations. No frameworks; matched scikit-learn on both.
Two learning paradigms, built from NumPy up. Part 1 is spam classification via decision trees (a single tree, then Random Forest, then AdaBoost), tracing the bias-variance tradeoff with each step. Part 2 is movie recommendation via matrix factorization: SVD warm start, then Alternating Least Squares on the sparse observed entries. Both matched scikit-learn’s accuracy on the same datasets.
Part 1: Spam Classifier
Structure in the Data
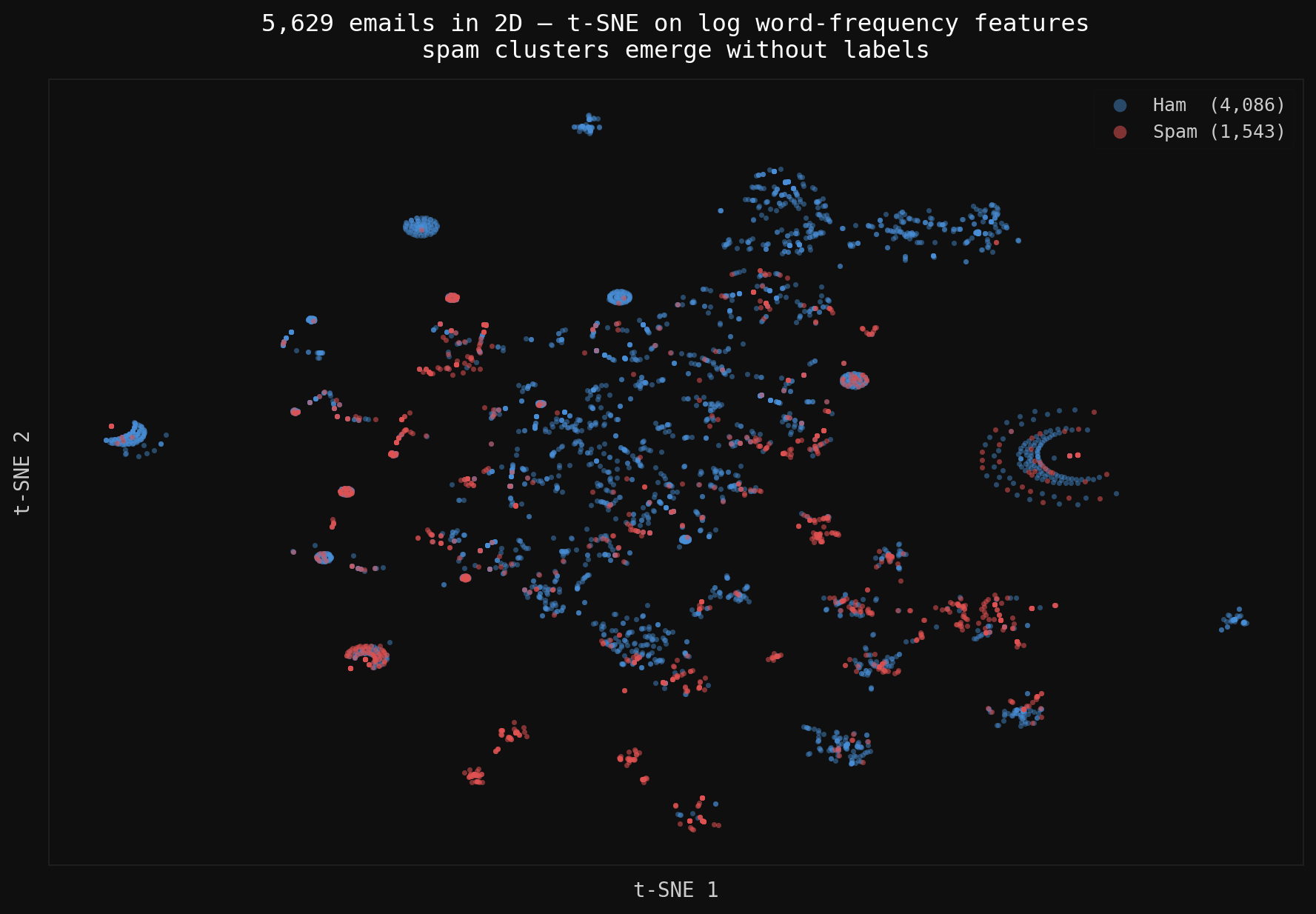
The t-SNE above maps 5,629 emails onto log-transformed word frequencies. Spam and ham aren’t cleanly separable in feature space (they share the same vocabulary), but tight spam sub-clusters are visible. Those clusters are template spam: batches of near-identical emails. A single decision stump on “exclamation” already carves off a large chunk because those clusters are dense and coherent.
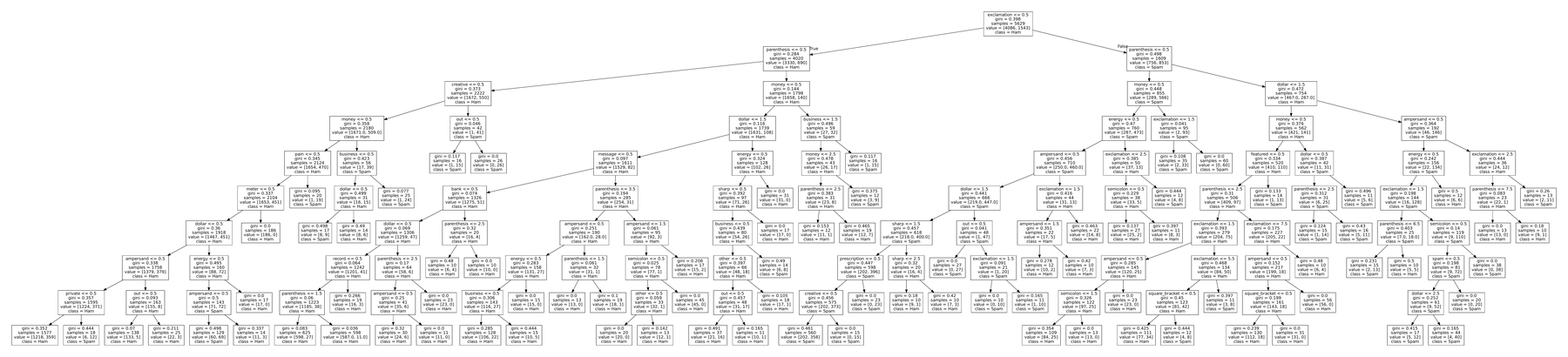
The full depth-9 tree: every internal node is a threshold on one word frequency. The tree was hand-grown by iterating information gain at each split:
Information gain over Gini impurity: both work similarly in practice, but information gain has a clean probabilistic interpretation (it measures bits of uncertainty removed), which makes it easier to reason about tree depth as a regularizer.
Feature Importance and Overfitting
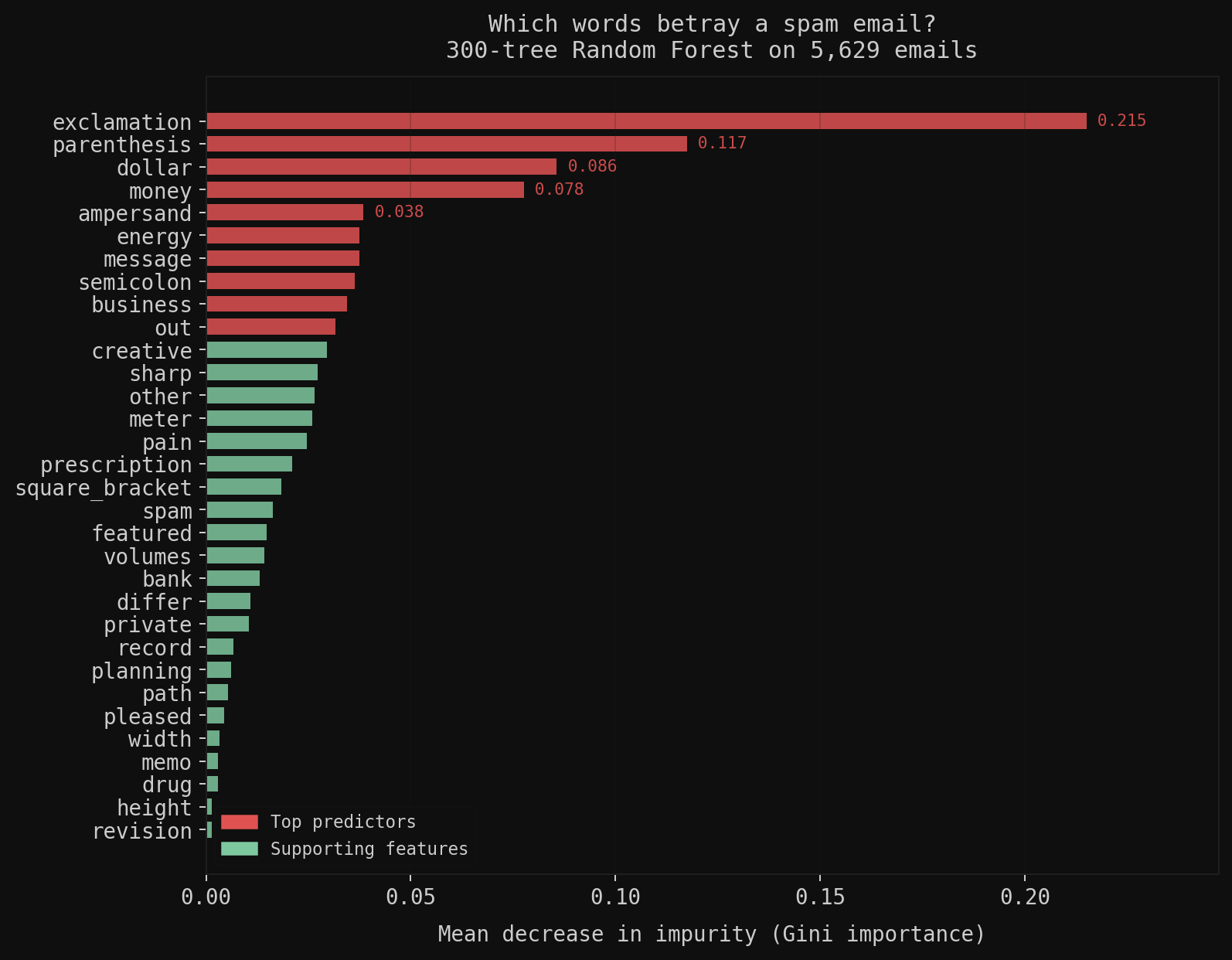
Exclamation mark frequency is the strongest single predictor, 3× more important than dollar signs. Spam writers use exclamation to manufacture urgency; legitimate email almost never does. “Parenthesis” and “semicolon” rank unexpectedly high because they appear as HTML formatting artifacts in the raw email corpus, a reminder that feature importance reflects what the model learned from this specific corpus, not linguistic truth.
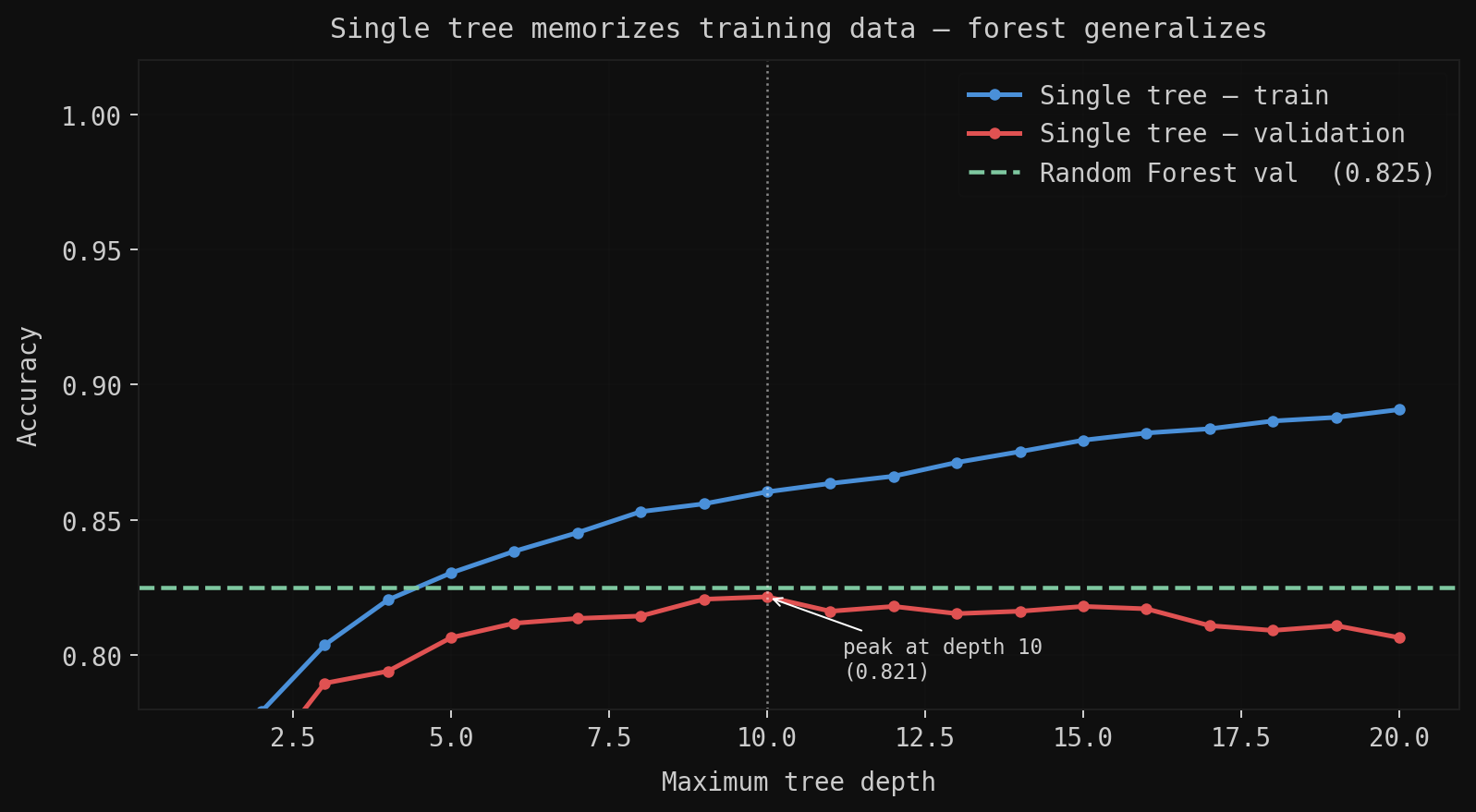
Left, single tree: training accuracy climbs to 100% while validation peaks at depth 10, then falls. The tree at depth 20 has memorized noise; it fits the training set perfectly by memorizing individual email quirks that don’t generalize.
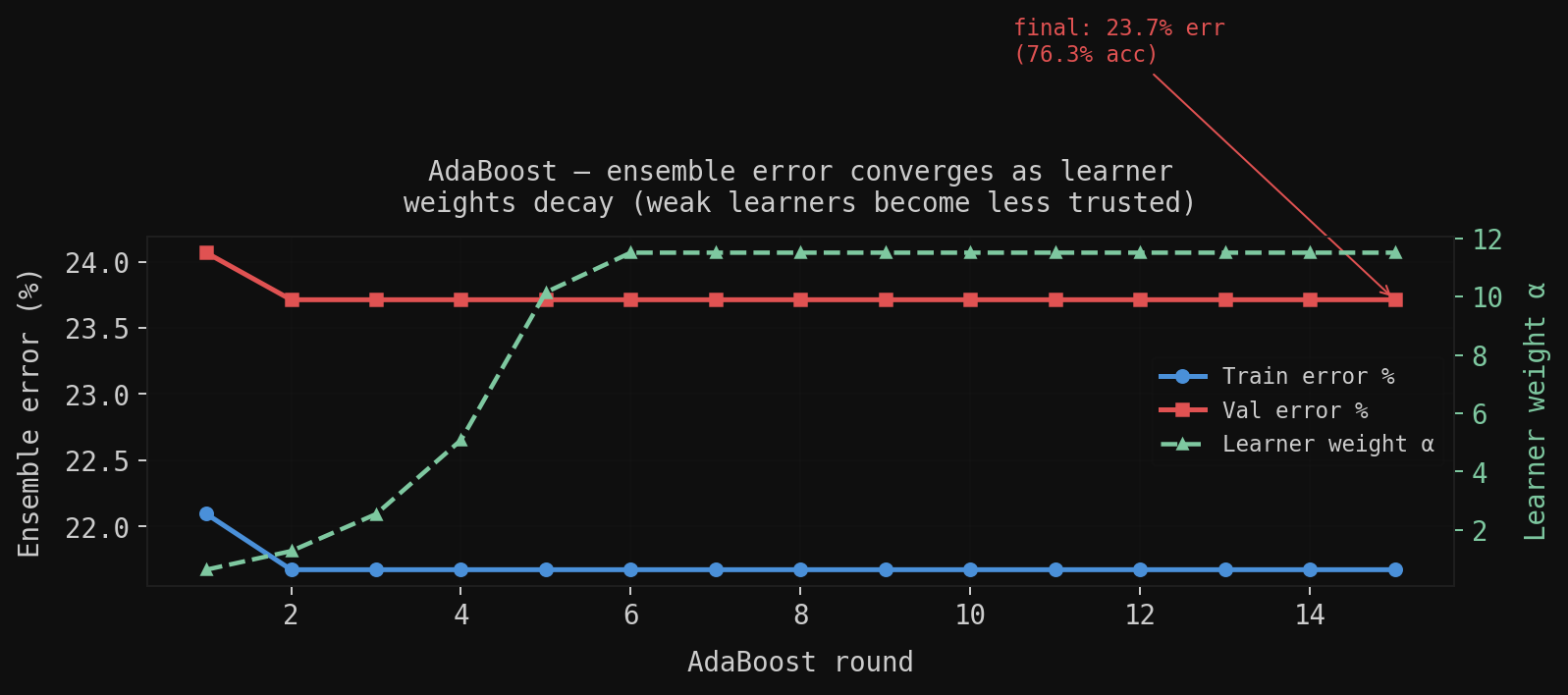
Right, AdaBoost: 15 rounds of depth-1 stumps drive validation error below the best single tree. Each stump’s weight decays because later rounds face the harder residual examples left by all previous rounds; the stumps are weaker, so they get less vote.
The Bias-Variance View
Three models, three positions on the same tradeoff. A depth-unrestricted tree is a high-variance estimator: zero training error, poor generalization, fitting every quirk of the training set. Random Forest attacks this with bagging: 200 trees each trained on a bootstrapped sample with a random feature subset at each split. Individual trees still overfit, but their errors are approximately independent and average out. The ensemble variance drops as (where is the number of trees) while bias stays roughly constant.
AdaBoost goes the other direction: depth-1 stumps are high-bias, low-variance; each stump can only express one linear threshold, so it underfits alone. Boosting drives bias down iteratively by reweighting examples: each round focuses on the mistakes of all previous rounds. The final model is a weighted vote of 15 stumps, each adding a little information the others missed.
Random Forest wins on robustness; AdaBoost wins on final accuracy on clean data but degrades faster when training labels are noisy (because it keeps amplifying the weights of mislabeled examples).
Part 2: Movie Recommender
The Problem is Sparsity

24,983 users × 100 movies, 64% empty. Each row is a user’s taste; each column is a movie’s reception. Sorted by mean rating, a faint diagonal gradient is visible (agreeable users cluster top-right, critical users bottom-left), but the structure is buried in the sparsity. The goal: fill in the blanks from the pattern of what is observed.
Factorization
Find low-rank matrices and minimizing reconstruction error on observed entries only:
Why ALS over SGD: Alternating Least Squares fixes and solves for each row of in closed form, then swaps. Each subproblem is ridge regression, , with a guaranteed global minimum per step. SGD on this objective is cheaper per iteration but needs careful learning rate tuning and doesn’t have the clean convergence guarantee. For a dense enough (we have ~36% observed), ALS converges reliably in 20–30 iterations.
SVD warm start: full SVD on the mean-imputed matrix provides an initial , in the right subspace. ALS then refines on observed entries only. Cold-starting ALS from random often takes 2× more iterations to reach the same validation RMSE.
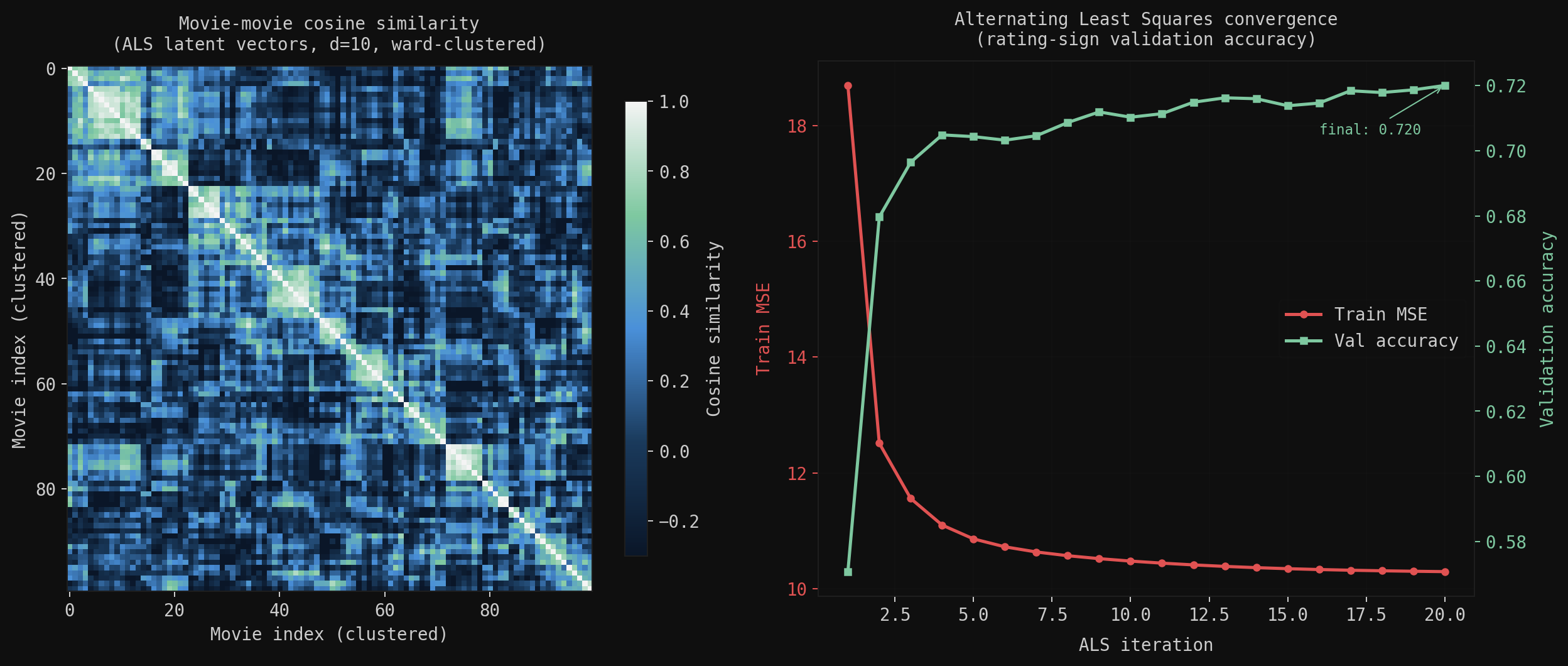
The cosine similarity heatmap (left) over learned movie vectors reveals genre clusters without ever seeing genre labels; the model infers them purely from rating co-occurrence. ALS convergence (right): train MSE drops sharply in the first 5 iterations and plateaus; validation accuracy (predicting rating sign) reaches 72% at latent dimensions and holds. Increasing beyond 20 improves training MSE but not validation, the classic sign of overfitting in low-rank models.
Related projects
Deep Learning from Scratch
The full arc: backpropagation in raw NumPy, CNNs with BatchNorm and Dropout trained to 78% on CIFAR-10, multi-head self-attention for text summarization, and a Masked Autoencoder that reconstructs images from 25% of their patches, then transfers those features to downstream tasks.

Entropy Wordle Solver
Information-theoretic greedy solver that picks each guess to maximize expected entropy over the remaining word set, averaging 3.92 guesses across 300+ games.

MCMC Cipher Decoder
Metropolis-Hastings breaking substitution ciphers against bigram frequencies. Watch garbled text slowly resolve into English over MCMC iterations.