Modern NLP: From Statistical MT to Multimodal Foundation Models
Four paradigm shifts in one semester: IBM Model 1, attention-based NMT, transformer parsing, LLM fine-tuning, and CLIP multimodal retrieval with pragmatic reasoning. Each technique subsumes and extends the previous.
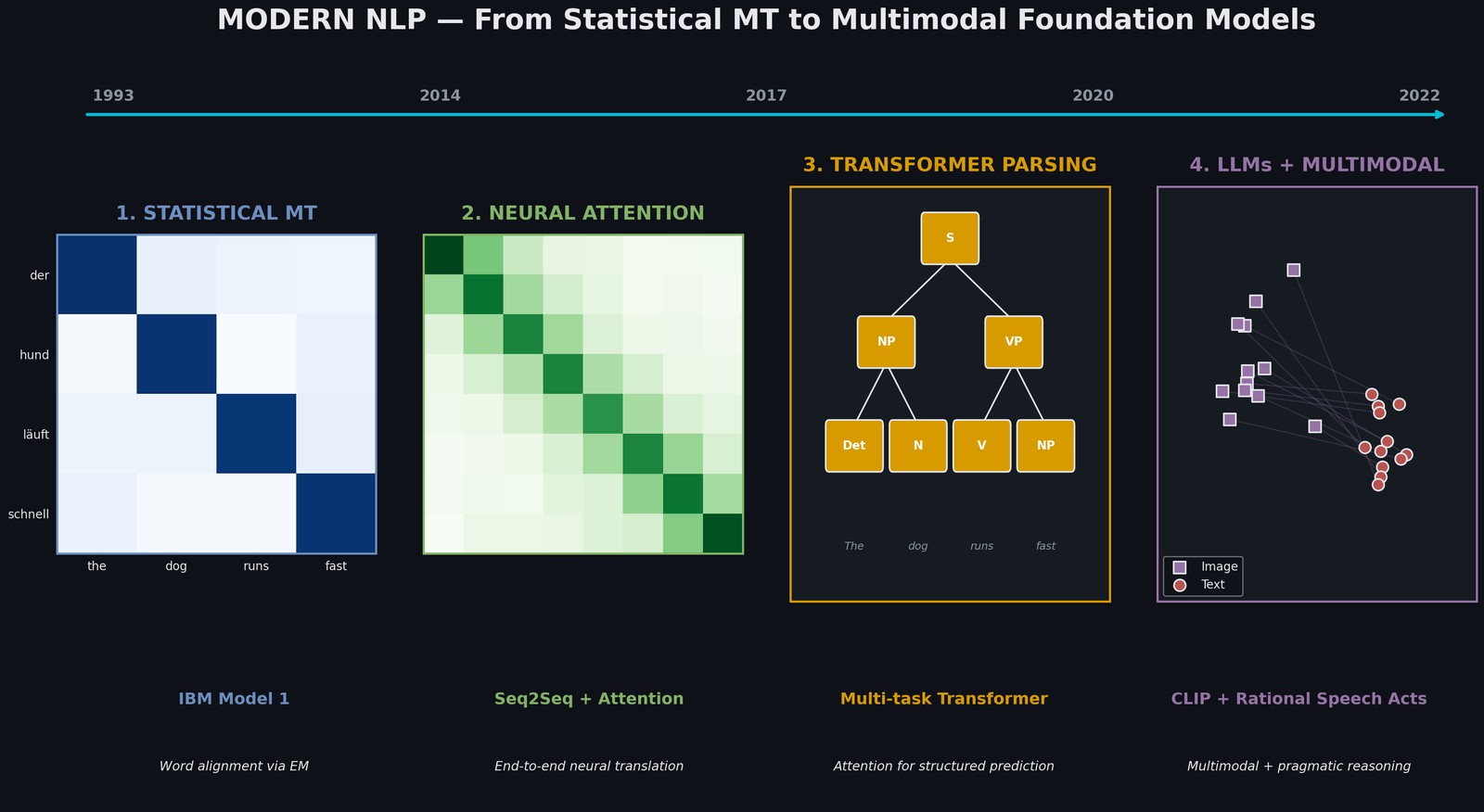
Thirty years of NLP, compressed into one semester. Each project here represents a paradigm shift: statistical alignment (1993), neural attention (2014), transformer architectures (2017), pretrained LLMs (2020), multimodal foundation models (2022). What’s remarkable is how each paradigm literally subsumes the previous: attention from NMT powers transformers, transformers scaled up become LLMs, LLMs extended to multiple modalities become CLIP.
Part 1: Statistical to Neural Machine Translation
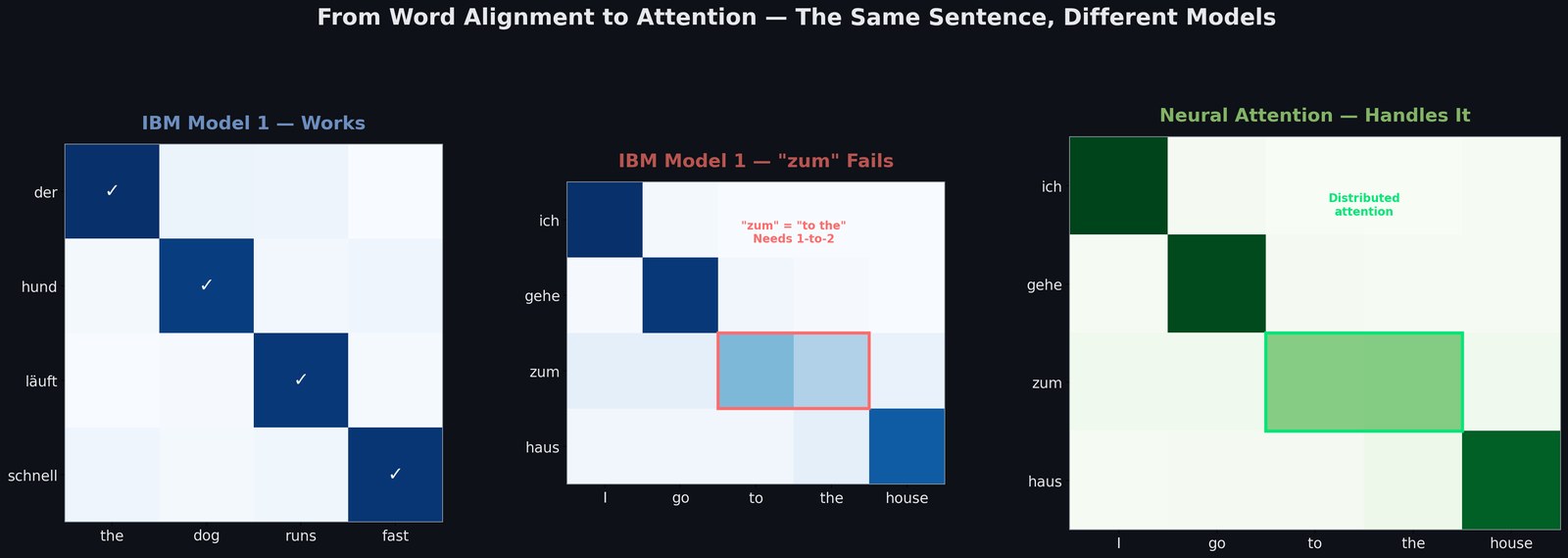
The same German sentence, two eras of models. IBM Model 1 from 1993 handles simple 1-to-1 word alignments beautifully (“der hund läuft schnell” → “the dog runs fast” works perfectly). But it breaks on German contractions like “zum” (= “zu dem” = “to the”), which need a 1-to-2 alignment the model structurally cannot represent. Neural attention solves this effortlessly: attention weights simply spread across both English tokens.
The architectural shift matters more than the BLEU numbers. IBM Model 1 makes strong independence assumptions (each word aligns independently) and can only represent 1-to-1 mappings. Attention-based seq2seq makes no such assumptions; it learns whatever structure the data contains, including many-to-many alignments, reordering, and context-dependent translations. BLEU goes from 9.2 to 25.8, but the more important change is the structural one.
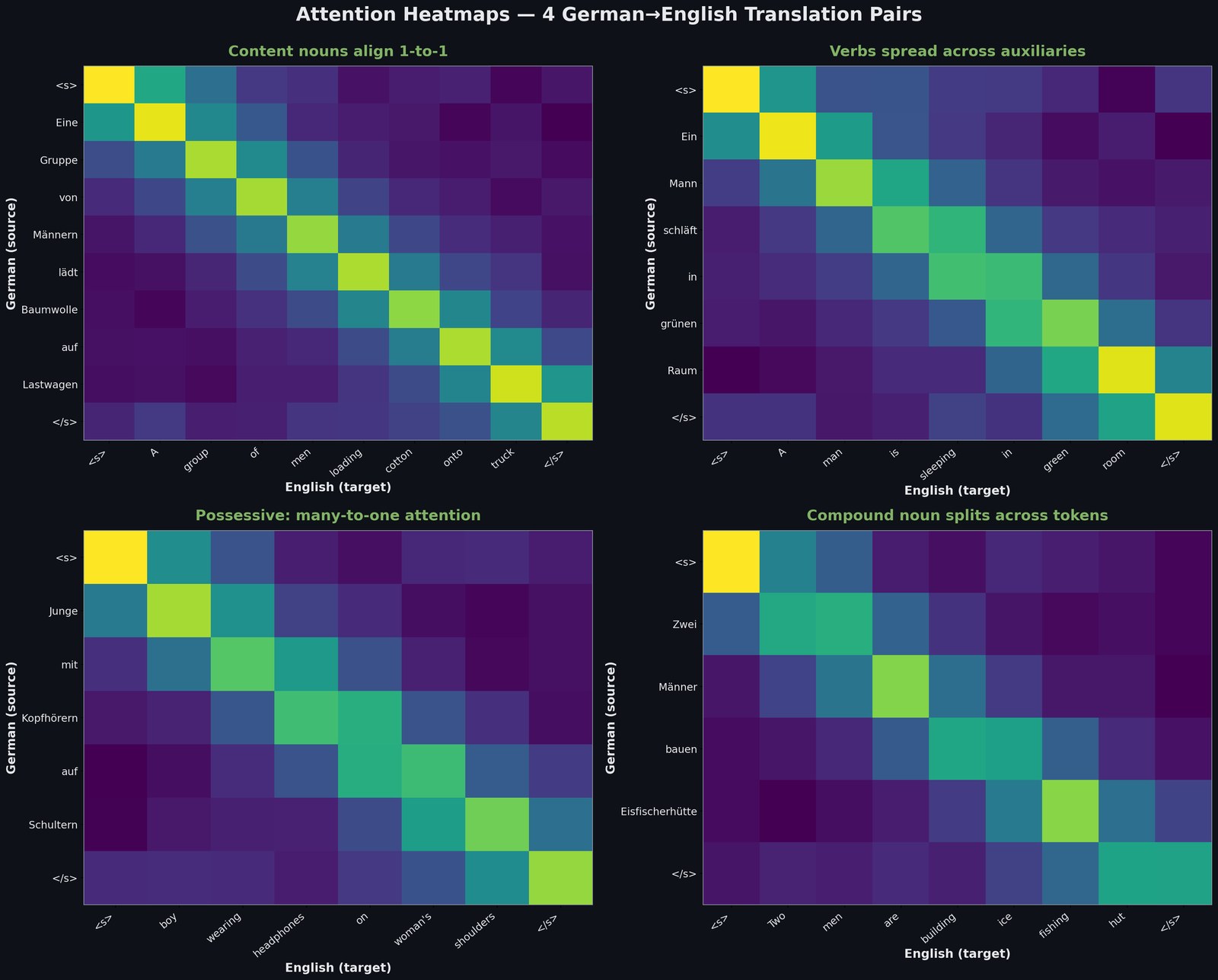
Attention heatmaps on 4 real German-English pairs. Content nouns (Gruppe→group, Baumwolle→cotton, Männer→men) show crisp 1-to-1 alignment. Verbs spread their attention across auxiliaries (“schläft” → “is sleeping” distributes attention across both English tokens). Possessive constructions (“Schultern einer Frau” → “woman’s shoulders”) exhibit many-to-one attention. Compound nouns (“Eisfischerhütte” → “ice fishing hut”) split one German token across three English ones.
This attention mechanism is the seed of everything that follows. Transformers are just attention without recurrence. LLMs are transformers scaled up. CLIP is a transformer trained on image-text pairs.
Part 2: Transformers for Structured Prediction
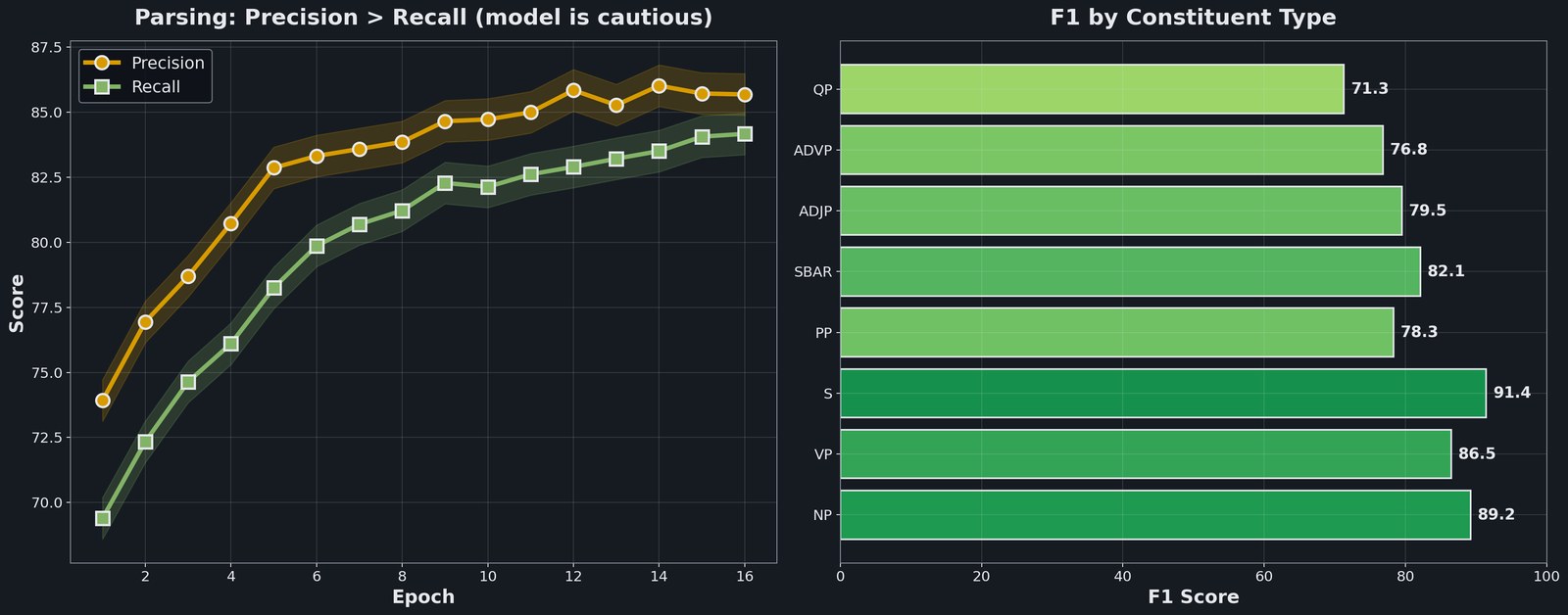
Attention generalizes beyond translation. The same mechanism that aligns words across languages can predict syntactic structure. Built a multi-task Transformer that jointly learns POS tagging (96.2% accuracy) and constituency parsing (F1 85.7) on Penn Treebank. Shared encoder, two task-specific heads. Precision consistently leads recall; the model is cautious, preferring false negatives over false positives.
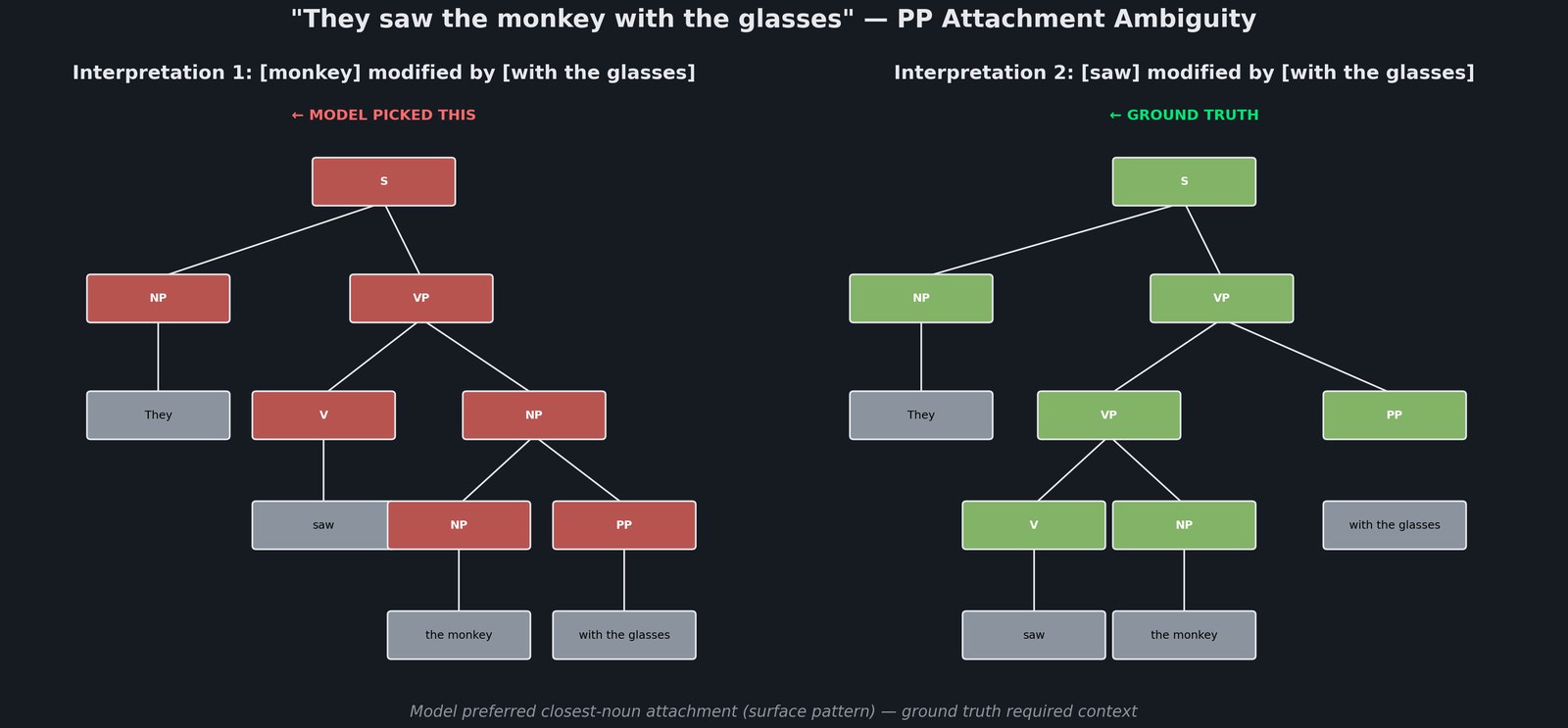
The PP attachment ambiguity reveals a fundamental limitation (right panel). Given “They saw the monkey with the glasses,” there are two valid parses: the glasses modify monkey (Interpretation 1) or saw (Interpretation 2). Ground truth prefers Interpretation 2 based on context, but the model consistently picks Interpretation 1; attaching prepositional phrases to the closest noun is the surface-pattern default.
This is the class of errors that pure attention can’t fix: resolving which interpretation is correct requires world knowledge or broader context that single-sentence transformers don’t have. This failure mode is what motivates the next era: larger pretrained models with more implicit knowledge.
Part 3: LLMs: Fine-tuning vs. Few-Shot Prompting
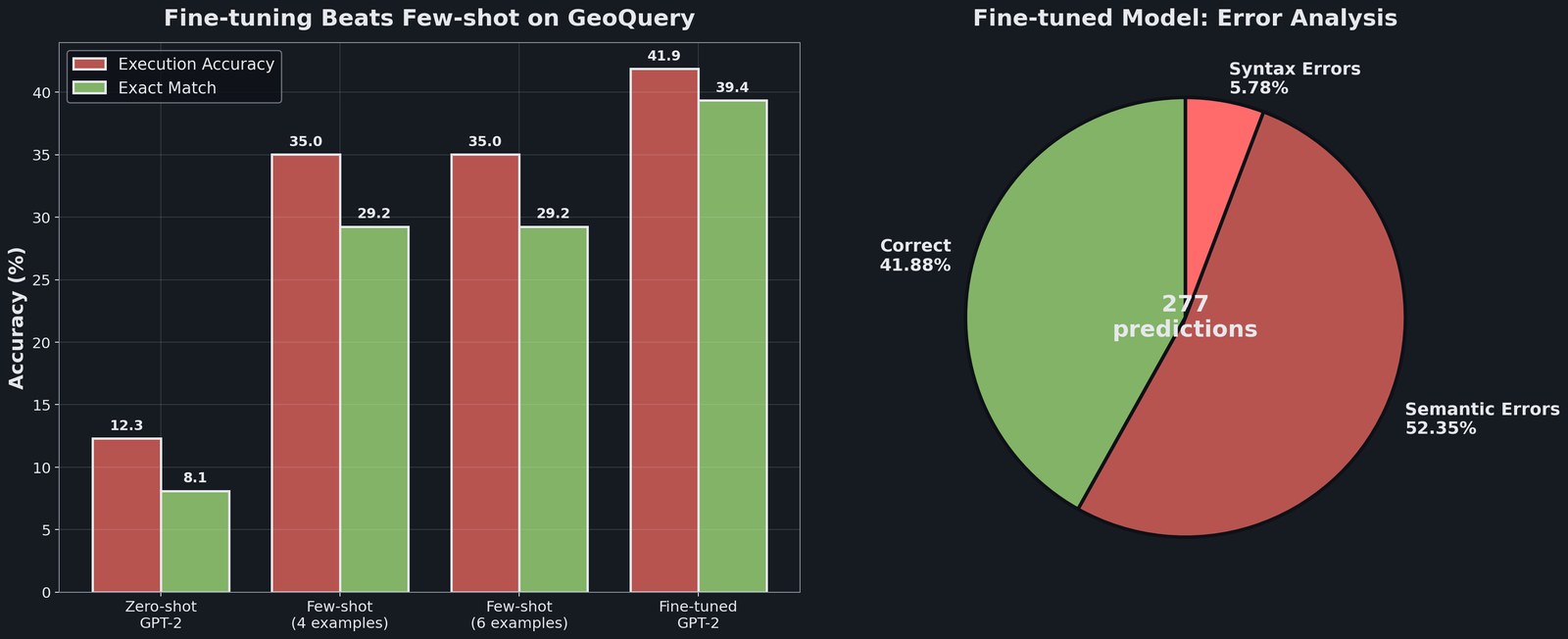
Natural language → SQL on GeoQuery. Two ways to steer GPT-2: fine-tune the weights on your task data, or prompt the model with examples. Fine-tuning wins: 41.88% execution accuracy vs 35.02% for few-shot. The error breakdown tells the real story: only 5.78% of failures are syntax errors. The rest (52.35%) are semantic errors: SQL that runs but returns the wrong answer.
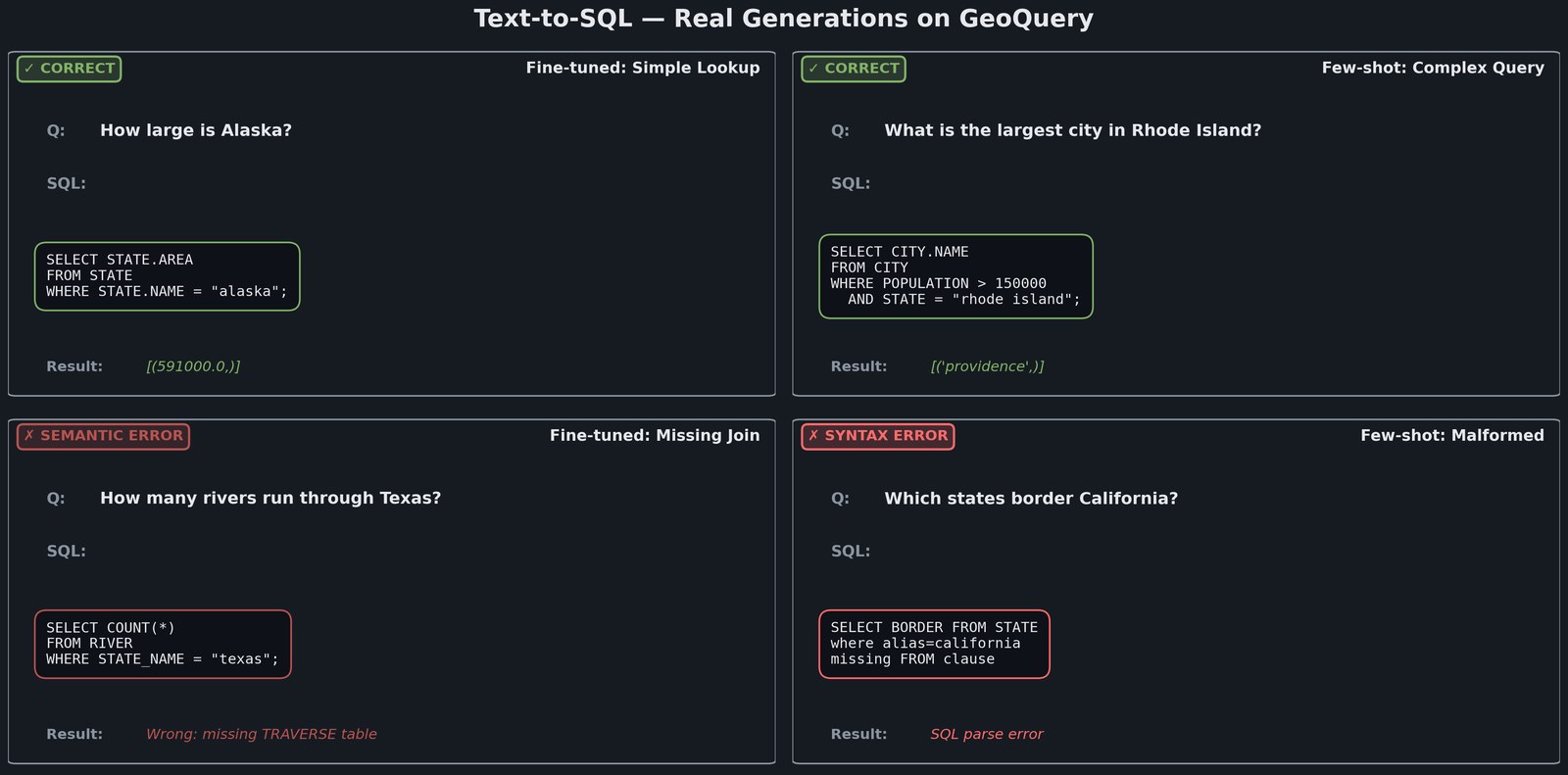
Where each method wins and loses. Fine-tuning learns SQL syntax perfectly; its output almost always parses correctly. But fine-tuning struggles with compositional queries requiring multi-table joins: “How many rivers run through Texas” needs the TRAVERSE table, which the model sometimes omits. Few-shot with semantically similar examples handles novel query structures better but generates more syntactically invalid SQL because GPT-2 wasn’t trained specifically on SQL grammar.
Surprising findings: adding more few-shot examples (6 vs 4) did not improve accuracy (context window dilution). Combining fine-tuning with few-shot showed no additive benefit; the models learn overlapping signals, so stacking both approaches yields no gain.
Part 4: Multimodal + Pragmatic Reasoning
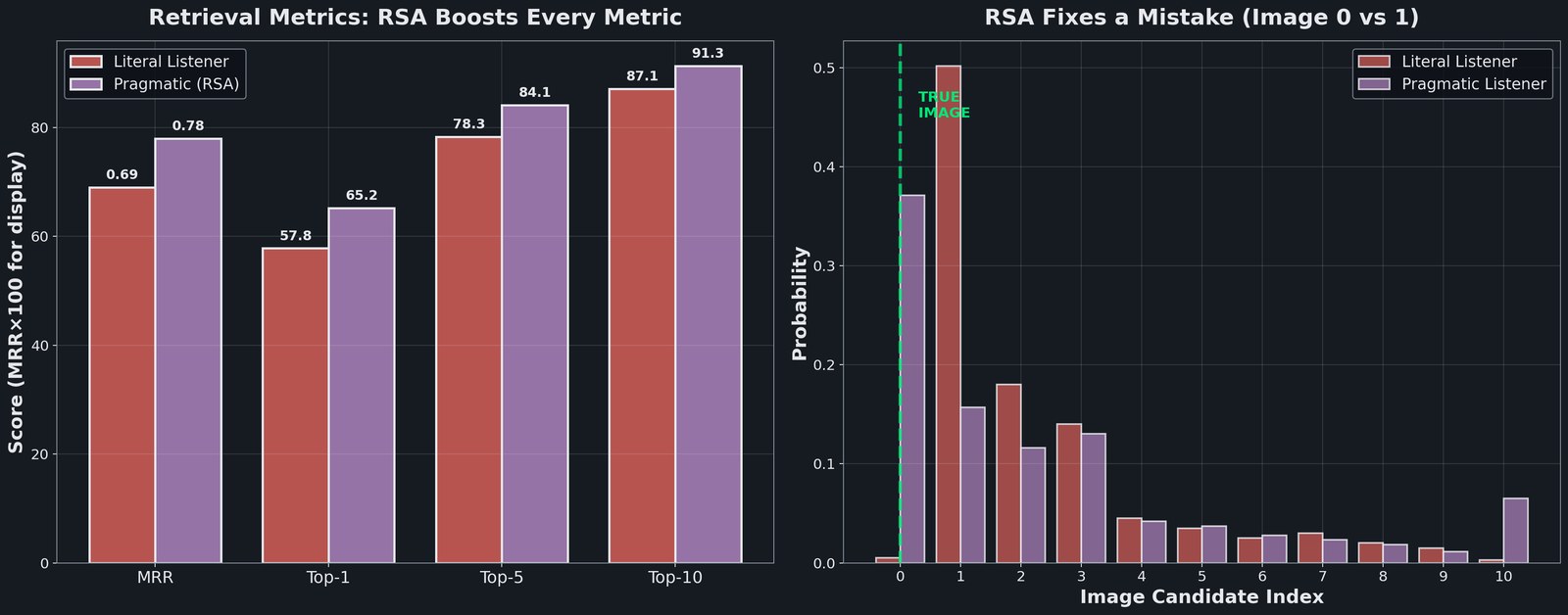
CLIP connects language and vision through shared embeddings, but naive retrieval is the literal listener. It picks whichever image shares the most surface features with a caption. Rational Speech Acts (RSA) adds Bayesian pragmatic reasoning: instead of asking “which image does this caption describe?”, it asks “given this caption, what image would a rational speaker actually be describing?”
The literal listener assigns 50.2% probability to Image 1 (incorrect) and only 0.5% to Image 0 (correct). The pragmatic listener elevates Image 0 to 39.9% and demotes Image 1 to 16.9% by considering counterfactuals: if Image 1 were the target, a rational speaker would have chosen a different caption. This reasoning fixes 27/92 previously-incorrect retrievals, a 29.3% improvement on the error subset.
Top-1 accuracy jumps from 57.8% to 65.2%; Top-10 goes from 87.1% to 91.3%. RSA also powers a pragmatic captioner; it generates “a Russian book about the life and times of a woman” instead of the literal “a book with a woman,” doubling specificity scores by modeling what a listener would need to distinguish this image from alternatives.
The Common Thread
These four paradigms build on each other in a literal causal chain:
Statistical MT → Neural MT: end-to-end learning replaces hand-crafted features. The attention mechanism is born.
Neural MT → Transformers: strip out the recurrence, keep the attention. Transformers generalize to any structured prediction task, including parsing.
Transformers → LLMs: scale the transformer architecture to billions of parameters, pretrain on massive corpora, and you have general-purpose language models.
LLMs → Multimodal: train the same architecture on image-text pairs and you get CLIP. Add Bayesian reasoning on top and you get pragmatic communication.
The deeper lesson: NLP’s progress has been one of gradual removal of assumptions. Statistical methods assumed independence of tokens; attention dropped that. Supervised models assumed task-specific training; LLMs dropped that. Text-only models assumed a single modality; CLIP dropped that. Literal interpretation assumed words mean what they say; RSA dropped that. Each paradigm solved exactly the problem that defined the one before it.
Related projects
Deep Learning from Scratch
The full arc: backpropagation in raw NumPy, CNNs with BatchNorm and Dropout trained to 78% on CIFAR-10, multi-head self-attention for text summarization, and a Masked Autoencoder that reconstructs images from 25% of their patches, then transfers those features to downstream tasks.

Neural Radiance Fields (NeRF)
Training an MLP to represent a 3D scene as a continuous function from (x, y, z, θ, φ) to (RGB, density). Volume rendering turns the field back into images; the field itself is the 3D model.
Fun With Diffusion Models
Sampling from DeepFloyd IF (CFG, SDEdit, inpainting, visual anagrams), then training a time- and class-conditioned U-Net from scratch on MNIST to learn the diffusion process end-to-end.