MCMC Cipher Decoder
Metropolis-Hastings breaking substitution ciphers against bigram frequencies. Watch garbled text slowly resolve into English over MCMC iterations.

The Problem: Given a substitution cipher with 27! possible permutations (~10²⁸ states), how can we efficiently search this astronomical space to decode encrypted text? Traditional frequency analysis fails on short messages, and brute force is computationally impossible.
The Solution: Treat cipher-breaking as a Bayesian inference problem. Use Metropolis-Hastings MCMC to sample from the posterior distribution of ciphers, guided by English language statistics extracted from literary corpora.
Algorithm
The Metropolis-Hastings procedure transforms an intractable combinatorial search into a guided random walk through cipher space:
- Start from chaos: initialize with a random permutation; decoded text is complete gibberish
- Propose local changes: swap two letters in the current cipher, producing a neighboring permutation
- Accept based on likelihood: if the proposed cipher decodes the message to more English-like text (), accept always; if worse, accept with probability
- Iterate: the chain drifts toward high-likelihood ciphers, i.e. those that produce plausible English
Because the proposal distribution is symmetric (swapping A↔B is equally likely as B↔A), the Hastings correction cancels and the acceptance ratio simplifies to the likelihood ratio alone:
The stochastic acceptance is critical; it lets the chain escape local optima that a hill-climber would be trapped in permanently.
Language Modeling
The likelihood function is a bigram model learned from War and Peace (100k lines, 3.2MB). Rather than crude unigram letter frequencies, it captures character transition probabilities, the statistical fingerprint of English.
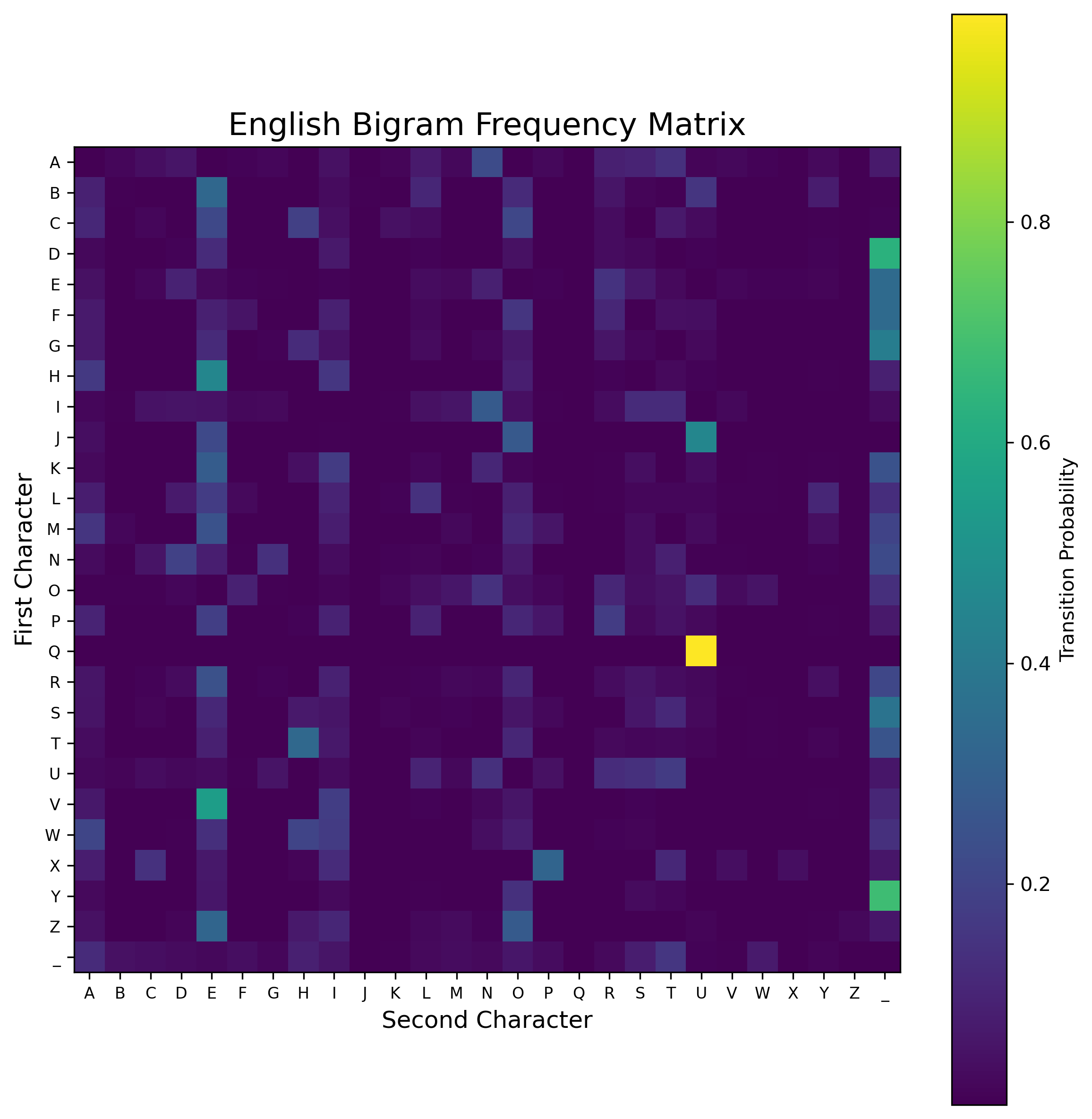
The Q→U cell glows brightest (yellow): “Q” is followed by “U” ~95% of the time in English. High-frequency transitions like TH, ER, ON, IN (warm blue) are common letter pairs. Near-zero transitions like QX, ZJ (dark purple) are essentially impossible in English. The likelihood under a proposed cipher is:
where is the 27×27 transition matrix and is the -th character of the ciphertext. Computing in log-space and using for the ratio avoids underflow on 500+ character sequences.
Laplace smoothing: add 1 to all bigram counts before normalizing, so no transition has probability zero. Without this, a single impossible bigram produces and the chain gets permanently stuck.
Convergence & Analysis
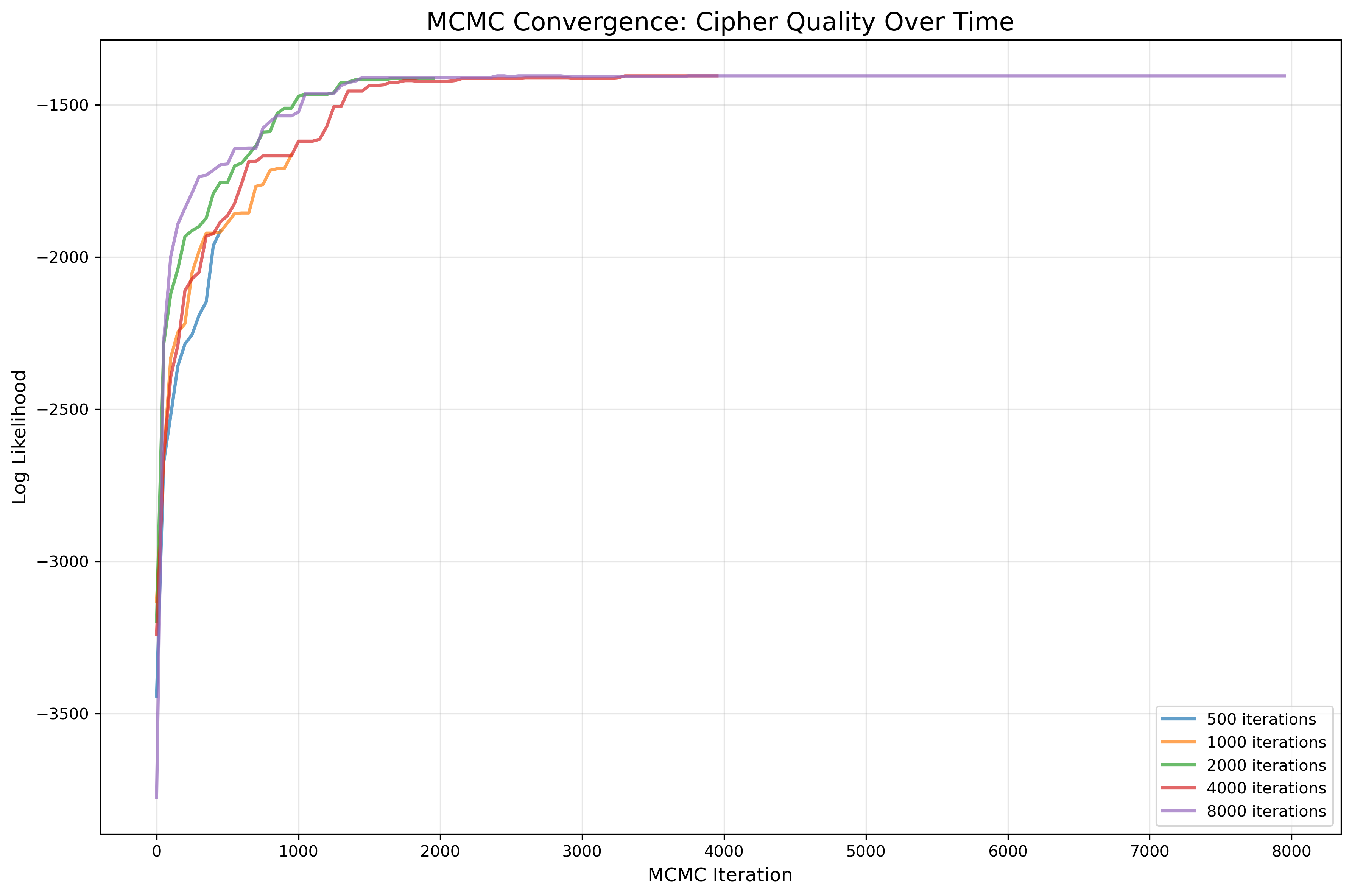
Five independent chains (left) all converge to the same log-likelihood plateau around iteration 2,000, regardless of starting permutation. The rapid rise corresponds to the burn-in phase; early swaps almost always improve the cipher because starting from random, any change is likely helpful. As the chain approaches the high-likelihood region, improvements become harder to find.
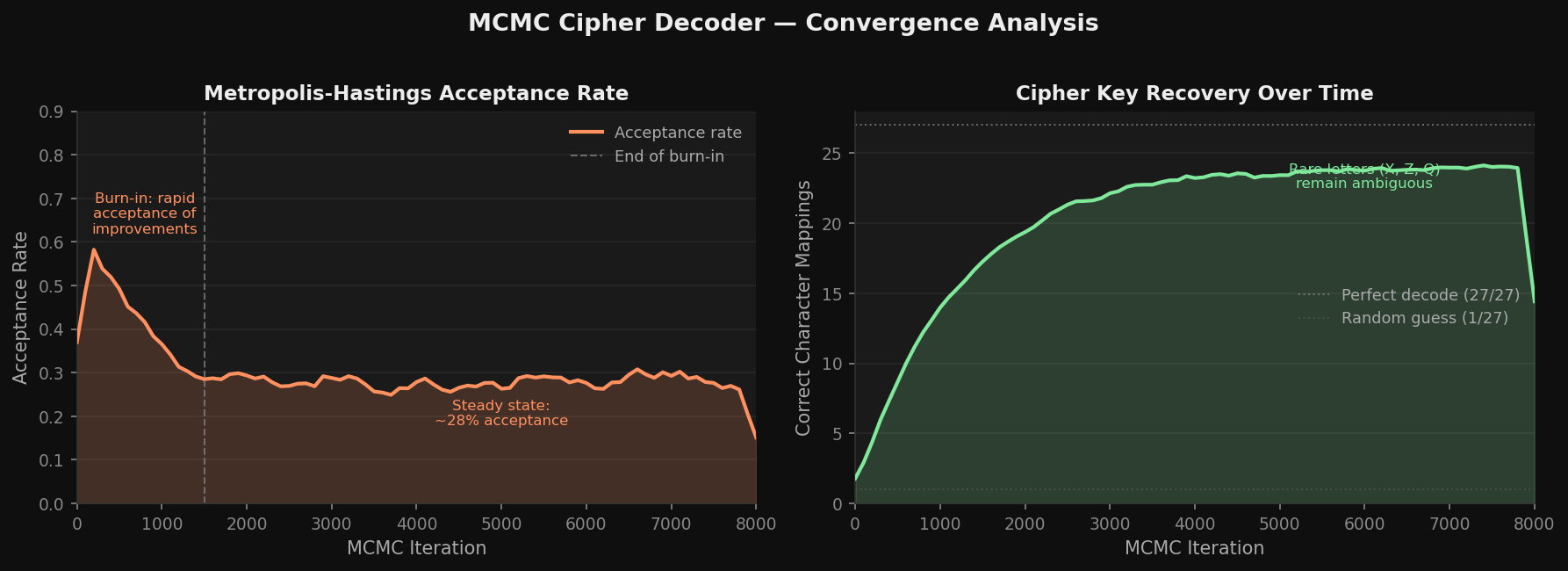
The right pair shows the two complementary diagnostics: acceptance rate drops from ~60% early (many improvements available) to a steady ~28% at convergence (most proposals are lateral moves or slight regressions). Correct character mappings climb from 1/27 (random) to ~24/27 by 8,000 iterations; the remaining 3 characters are rare letters (X, Q, Z) that appear too infrequently to get reliable bigram signal.
Decoding Evolution

The algorithm doesn’t decode linearly. At 500 iterations (orange row), the chain has found vowel/consonant structure (you can see word-like groupings), but most letters are still wrong. At 1,000 iterations, “AMOIN US” is already recognizable as “AMONG US”. At 2,000, 90% of the text is correct but rare letters like W remain mapped incorrectly (“XHO” instead of “WHO”). By 8,000 iterations the message is fully recovered.
Failure modes: Three classes of errors resist the algorithm:
- Rare letter ambiguity: X, Z, Q appear so rarely that swapping their mappings barely changes ; the chain can’t distinguish correct vs. incorrect assignments
- Local minima: word clusters where one cipher maps three plausible words; the chain accepts and gets stuck at a local optimum that looks like valid English
- Short message vulnerability: with fewer than ~100 characters, the bigram statistics have too much variance to reliably distinguish the true cipher from nearby alternatives
Performance & Failure Analysis
Vs. frequency analysis: Unigram frequency (E is most common, map the most frequent cipher character to E, etc.) fails completely on a 538-character message; there’s too much variance for letter-frequency matching to work reliably at this message length.
Vs. hill climbing: A greedy hill-climber accepts only improving swaps. It reaches a local maximum much faster but gets trapped there permanently. MCMC’s stochastic acceptance ( with ) allows occasional downward moves, providing the escape mechanism that lets the chain explore the full posterior.
Vs. simulated annealing: Annealing would lower the acceptance temperature over time, trading exploration for exploitation. For this problem the fixed-temperature Metropolis-Hastings works well because the target distribution is unimodal; there’s essentially one correct cipher and the posterior concentrates around it.
The MCMC approach decodes the 592-character message in ~8,000 iterations (≈2 minutes on a laptop), handling any substitution cipher without cipher-specific preprocessing.
Extensions
The same framework applies to any discrete combinatorial optimization where a likelihood function over states can be defined from domain statistics:
- Vigenère cipher: extend to position-dependent bigram models keyed to the period
- Transposition cipher: change the state space from permutations to column orderings; proposals become column swaps
- Unknown-language decoding: swap in an n-gram matrix from any target corpus
The broader principle: when the true posterior is hard to compute but easy to evaluate (likelihood ratios only), Metropolis-Hastings converts a search problem into a sampling problem; sampling is tractable even when search is not.
Related projects

Entropy Wordle Solver
Information-theoretic greedy solver that picks each guess to maximize expected entropy over the remaining word set, averaging 3.92 guesses across 300+ games.
Deep Learning from Scratch
The full arc: backpropagation in raw NumPy, CNNs with BatchNorm and Dropout trained to 78% on CIFAR-10, multi-head self-attention for text summarization, and a Masked Autoencoder that reconstructs images from 25% of their patches, then transfers those features to downstream tasks.
Classical ML from Scratch
Two learning paradigms built from NumPy up: tree-based spam classification (decision tree, Random Forest, AdaBoost) and SVD/ALS matrix factorization for movie recommendations. No frameworks; matched scikit-learn on both.