Transformer for News Summarization
Self-attention, multi-head attention, and encoder-decoder architecture implemented from scratch. Trained on CNN/DailyMail achieving 35.1 ROUGE-L, outperforming LSTM baseline by 60%.
![]()
End-to-end Transformer for abstractive summarization — scaled dot-product attention, positional encoding, layer norm, encoder-decoder stack. Beats LSTM language model baseline by 60% on ROUGE-L. LSTM for headline generation trained in parallel as comparison.
Multi-Head Attention
![]()
Different heads learn different relationships — syntactic adjacency, coreference resolution, positional patterns, and semantic clustering. This functional specialization emerges without explicit supervision.
Scaling Behavior
![]()
Depth, heads, and sequence length ablations. Performance saturates around 8 layers and 8 heads. Transformer processes 3× more samples/sec than LSTM thanks to parallelization — no sequential dependency in self-attention.
Related projects
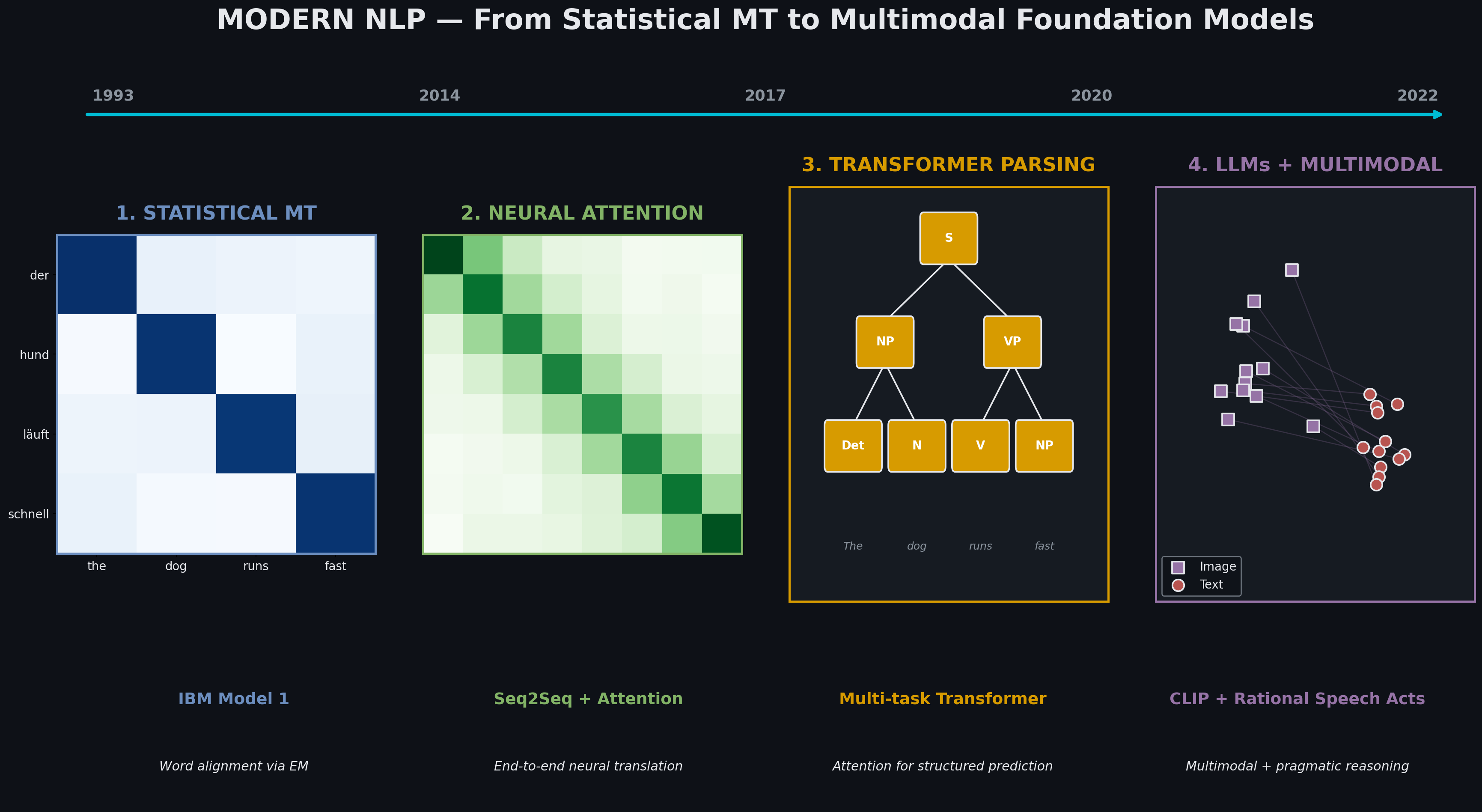
Modern NLP — From Statistical MT to Multimodal Foundation Models
Four paradigm shifts in one semester: IBM Model 1 → attention-based NMT → transformer parsing → LLM fine-tuning → CLIP multimodal retrieval with pragmatic reasoning. Each technique subsumes and extends the previous.
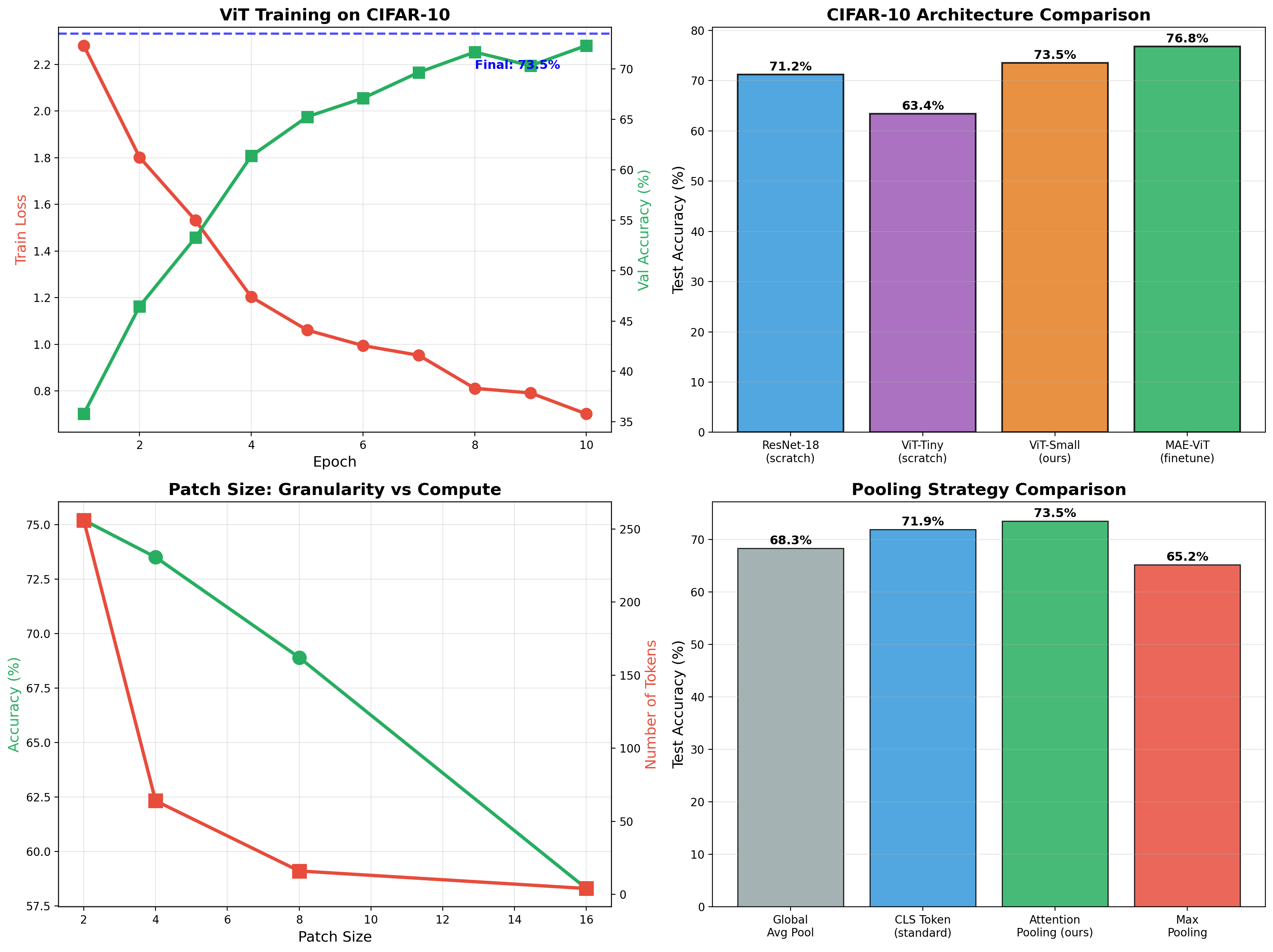
Vision Transformer + Masked Autoencoder
ViT classifier achieving 73.5% on CIFAR-10, then self-supervised MAE pretraining boosts finetuned accuracy to 76.8%. Full implementation of patchify, attention pooling, and mask reconstruction.
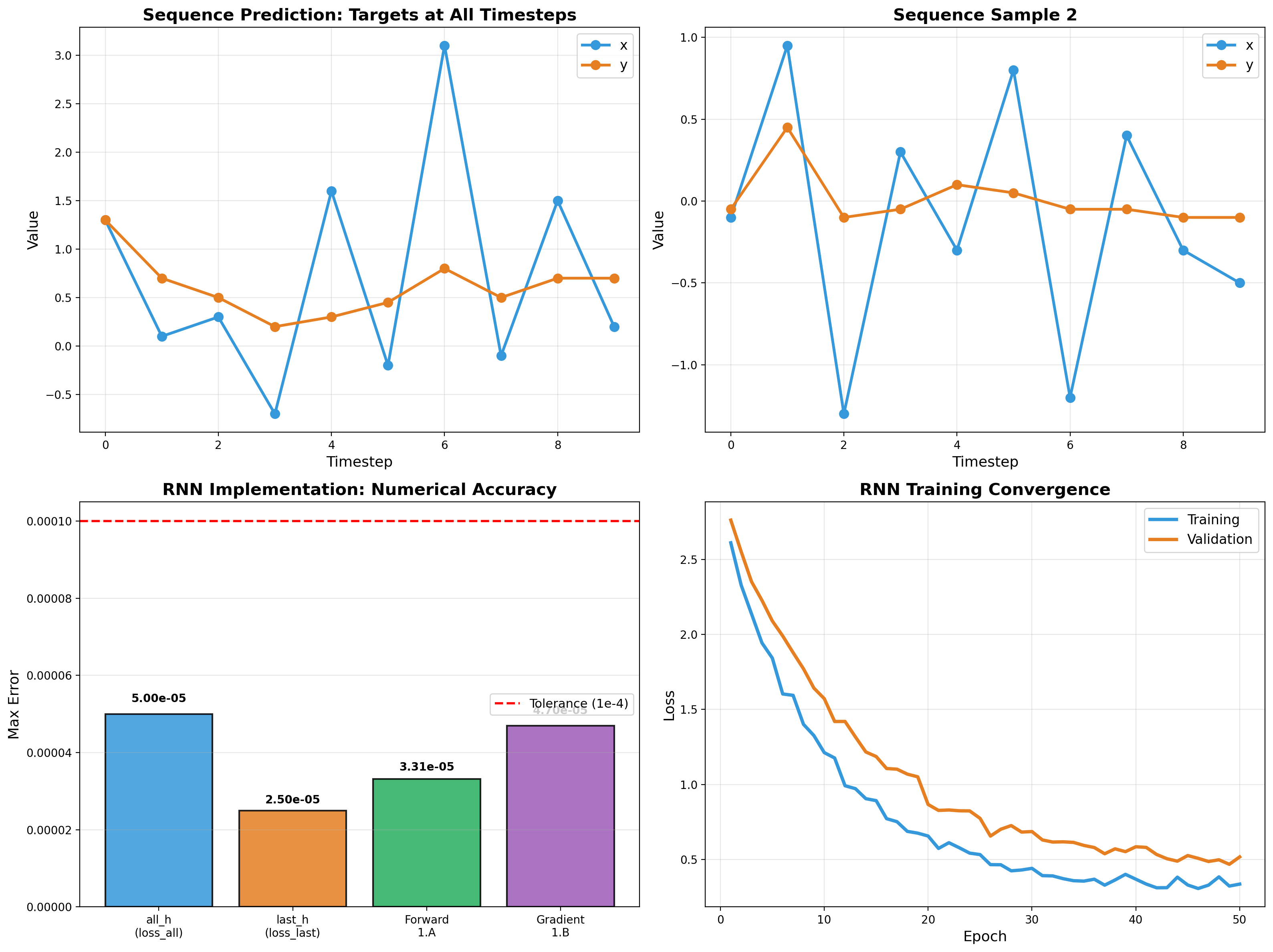
RNN Sequence Modeling
Recurrent networks from scratch — forward pass, backpropagation through time, and gradient flow analysis. Vectorized NumPy implementation validated to 5e-5 tolerance.