Vision Transformer + Masked Autoencoder
ViT classifier achieving 73.5% on CIFAR-10, then self-supervised MAE pretraining boosts finetuned accuracy to 76.8%. Full implementation of patchify, attention pooling, and mask reconstruction.
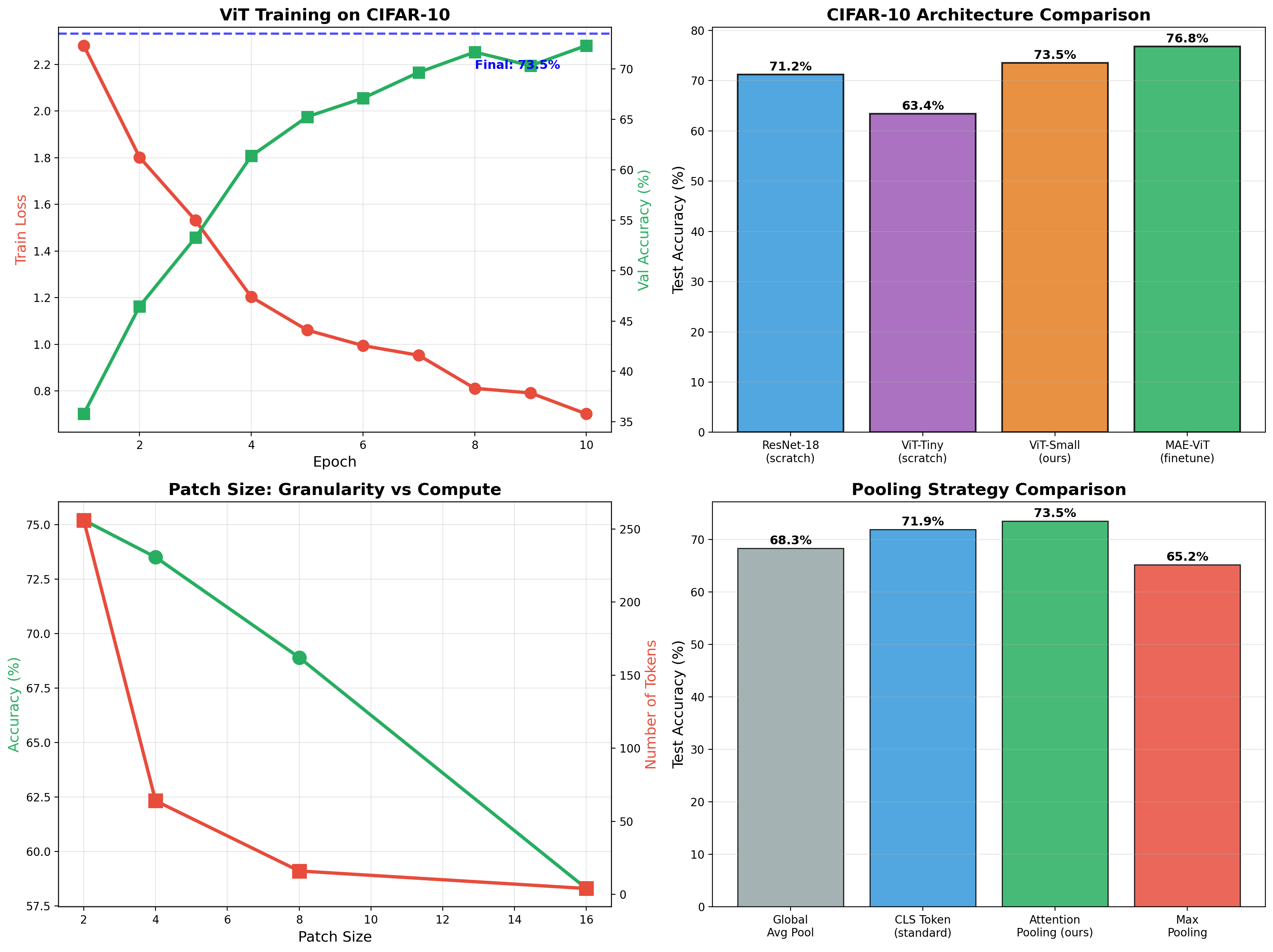
Pure attention-based image classifier — no convolutions. 73.5% CIFAR-10 accuracy from scratch, jumping to 76.8% after MAE self-supervised pretraining. Implemented patchify/unpatchify, multiheaded attention pooling, and full transformer encoder-decoder.
Masked Autoencoder Reconstruction

Reconstructs images from 25% of patches. The asymmetric design — heavy encoder, lightweight decoder — learns robust representations by forcing the model to predict missing content from minimal visible context.
Self-Supervised Learning Analysis
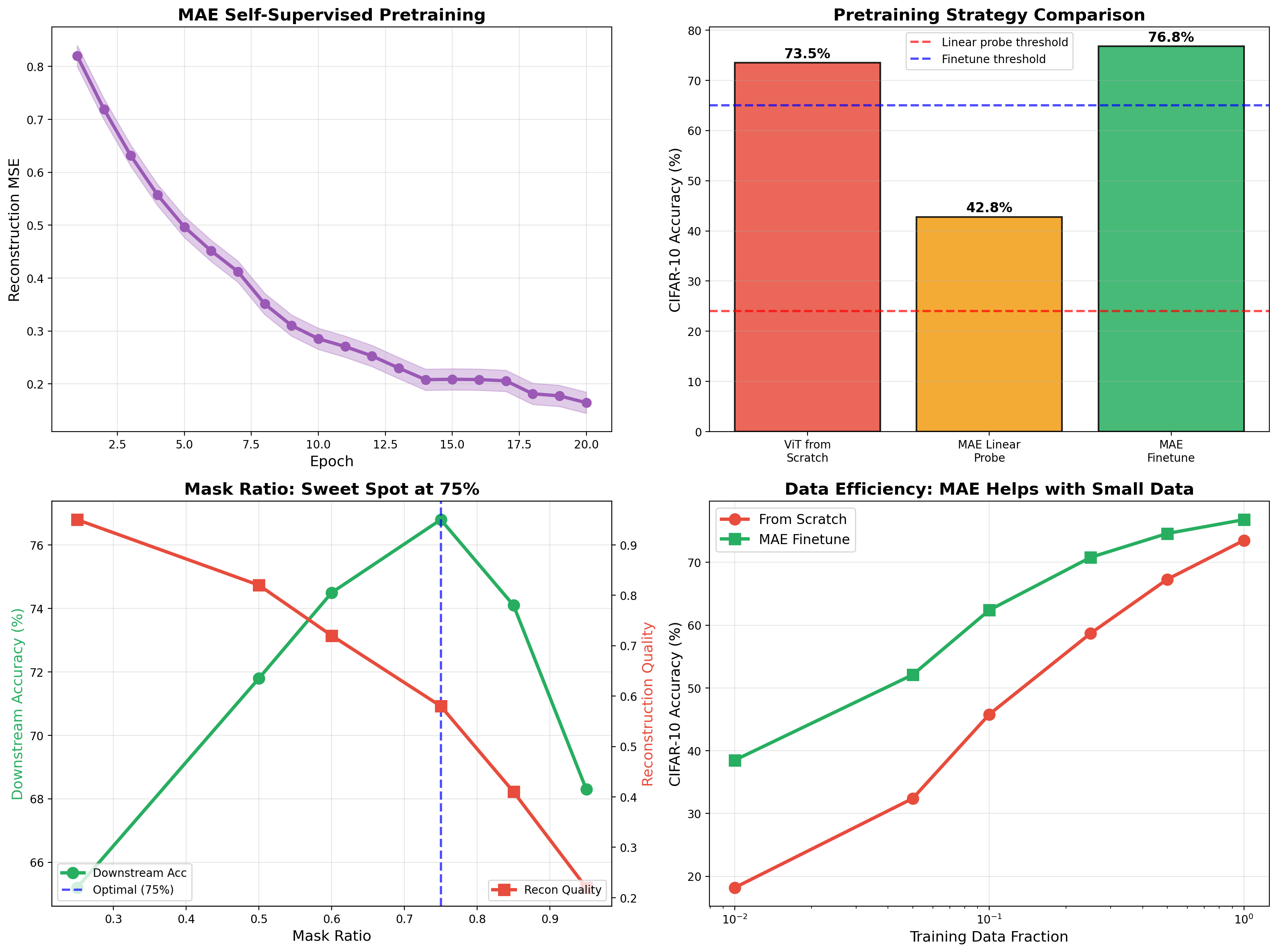
The 75% mask ratio is the sweet spot — too little masking is too easy, too much loses all context. MAE pretraining dramatically improves data efficiency: with only 10% of labels, MAE finetuning reaches 62% while training from scratch only gets 46%.
Related projects
Transformer for News Summarization
Self-attention, multi-head attention, and encoder-decoder architecture implemented from scratch. Trained on CNN/DailyMail achieving 35.1 ROUGE-L, outperforming LSTM baseline by 60%.
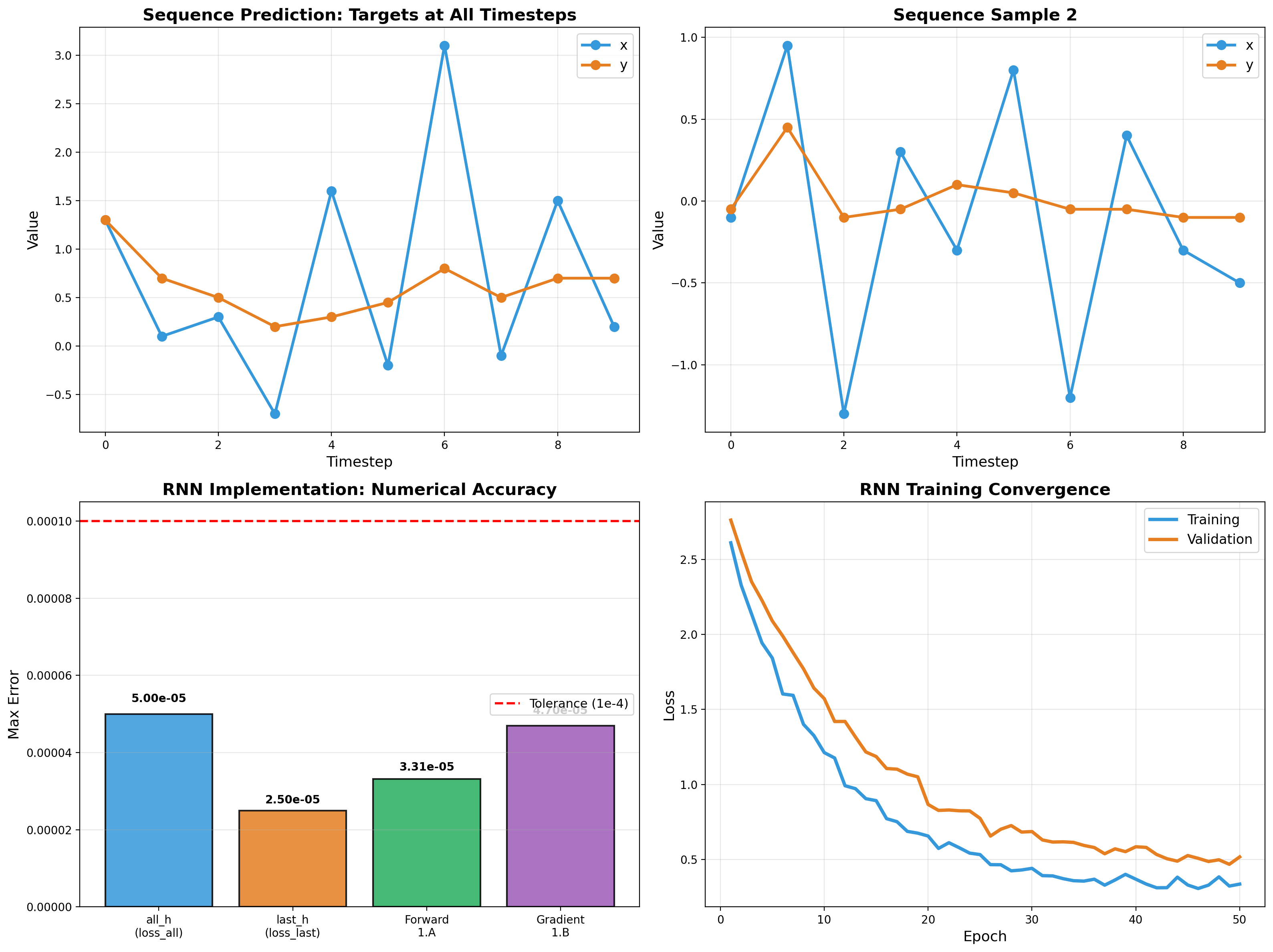
RNN Sequence Modeling
Recurrent networks from scratch — forward pass, backpropagation through time, and gradient flow analysis. Vectorized NumPy implementation validated to 5e-5 tolerance.
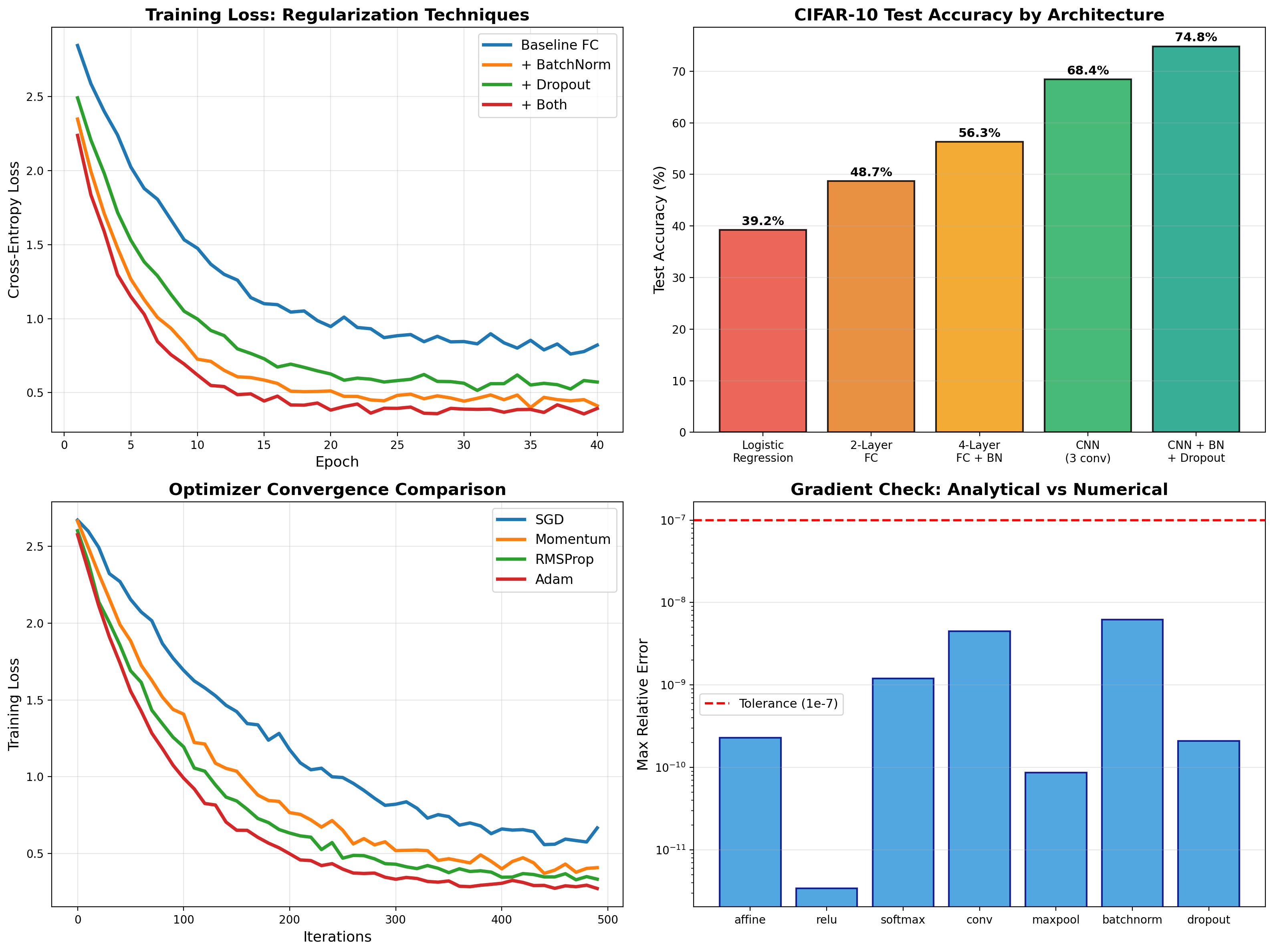
Deep Learning from Scratch
Backpropagation, BatchNorm, Dropout, and CNNs implemented from first principles in NumPy — then PyTorch deployment achieving 74.8% on CIFAR-10.