Multi-Agent RL for Autonomous Driving in Waymax
PPO agent trained in Google's JAX-based Waymax simulator on Waymo Open Dataset traffic. Began as speed tracking on log-replay traffic and ended as adaptive cruise control evaluated on a five-scenario stress suite: stalled vehicle, slow lead, emergency braking, stop-and-go, and cut-in. Four pass with zero contact; the fifth exposes a measurable generalization gap. Fourteen training runs, ten documented failure modes.
Stress Tests
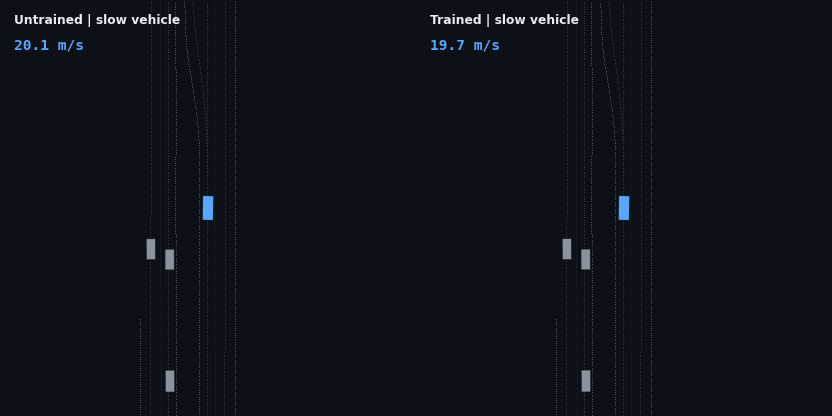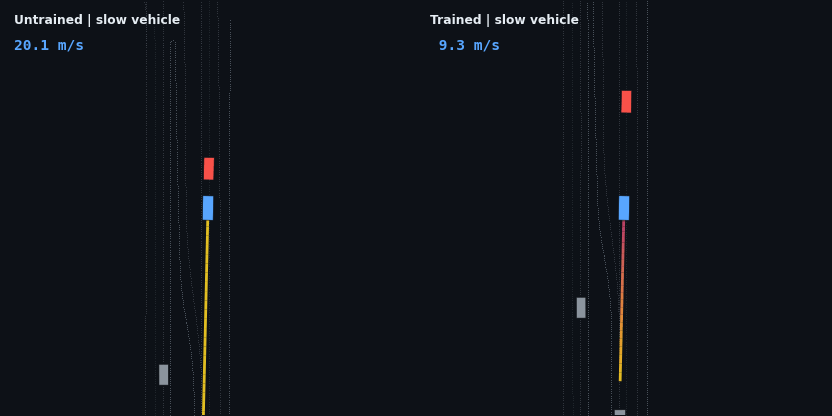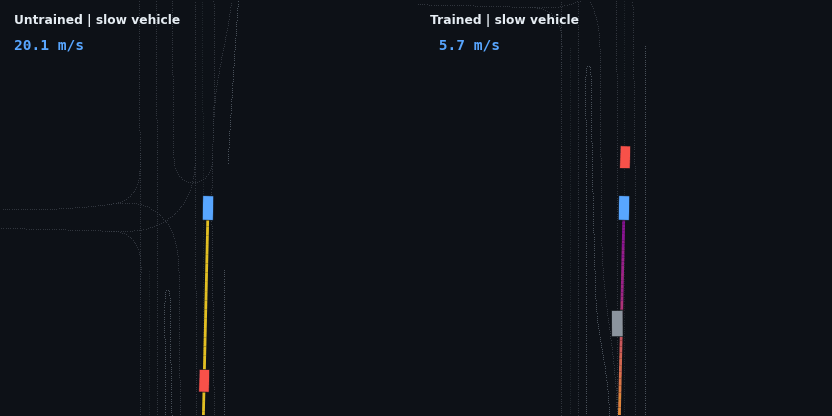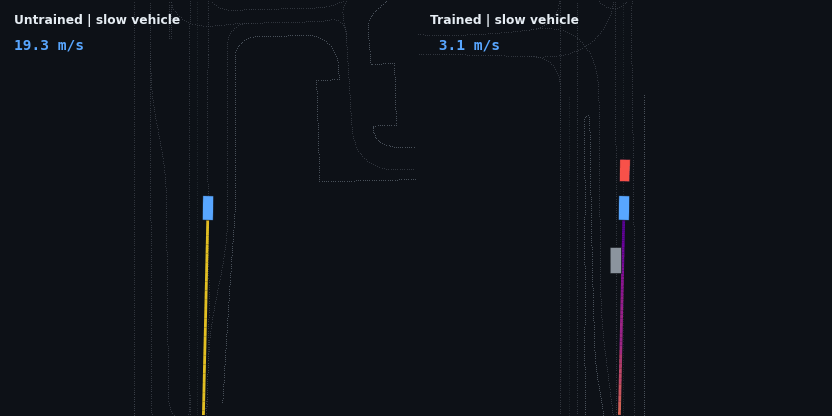
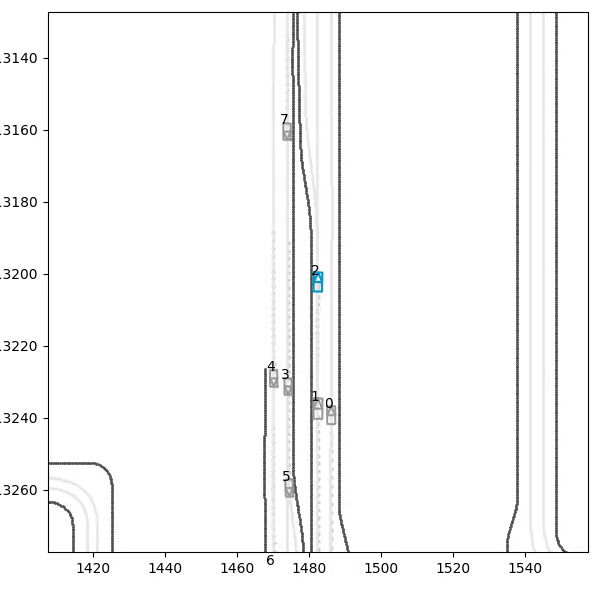
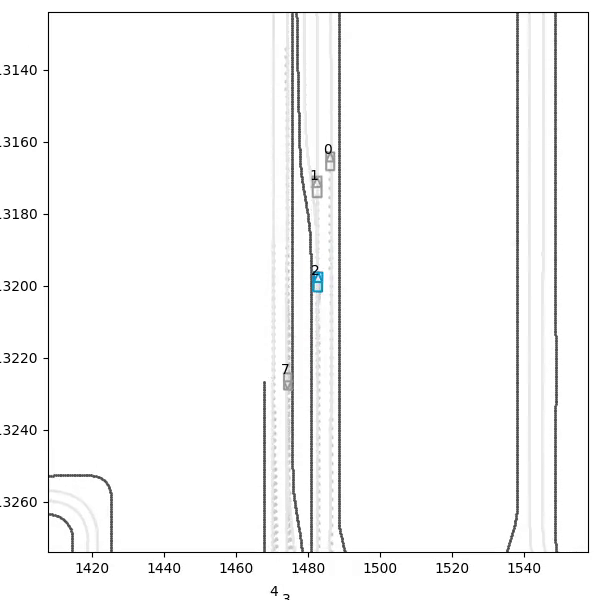
The headline result: the trained policy is evaluated on five injected hazard scenarios — counterfactual edits of the real WOD scenario, since Waymax has no synthetic scenario generator and the WOMD dataset is the sole data source. Each runs the trained and untrained policies side by side; the red vehicle is the scripted hazard, the ego trail is colored by speed.
| Test | Untrained | Trained |
|---|---|---|
| Stalled vehicle, 75 m ahead | drives through at 19.3 m/s | stops 10.9 m behind, 0 contact |
| Slow vehicle (3 m/s), 55 m ahead | drives through at 19.3 m/s | matches speed (3.1 m/s), follows at 8.2 m, 0 contact |
| Emergency brake (lead 8 m/s → 0) | collides, 7 contact steps | stops 8.5 m behind, 0 contact |
| Stop-and-go (stopped lead departs) | drives through at 19.3 m/s | brakes to 3.3 m/s, re-accelerates to follow, 0 contact |
| Cut-in (6 m/s lead merges in) | clips it in passing | reacts, slows 11 → 5 m/s, but follows 4 m too close: clips the lead |
The stalled vehicle is the hardest braking problem in the suite — a stationary obstacle approached at full speed — and the test that earlier policy generations failed in three different ways:
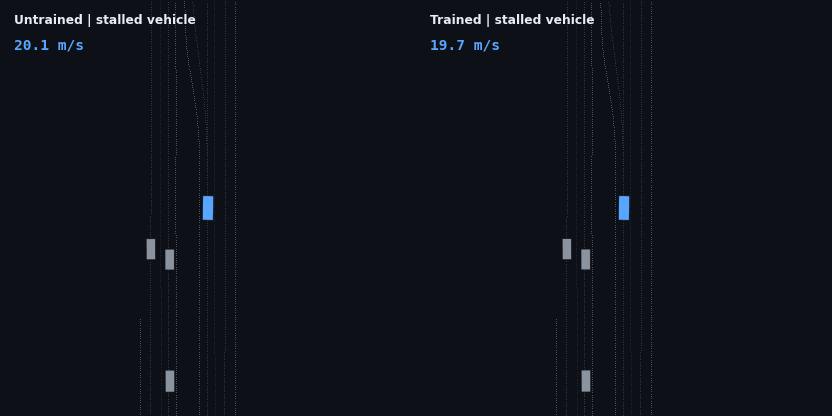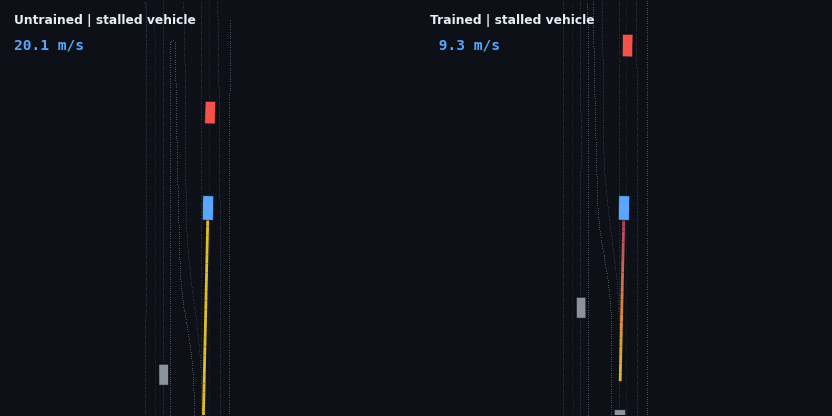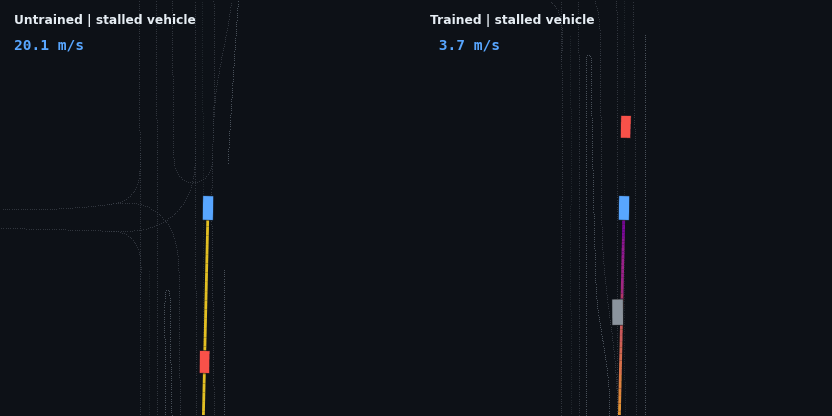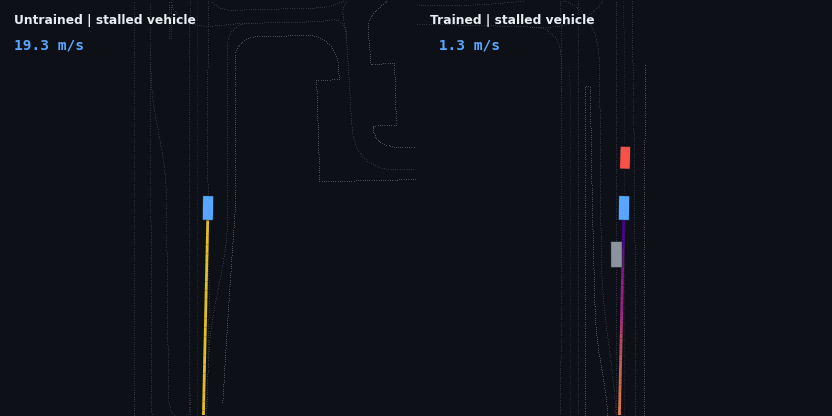
A moving lead changes the task from stopping to regulation: the agent has to find the lead’s speed and hold a stable gap rather than just shed velocity.
The next two are dynamic: the hazard changes behavior mid-episode, so the policy has to respond to a closing speed that appears while already following.
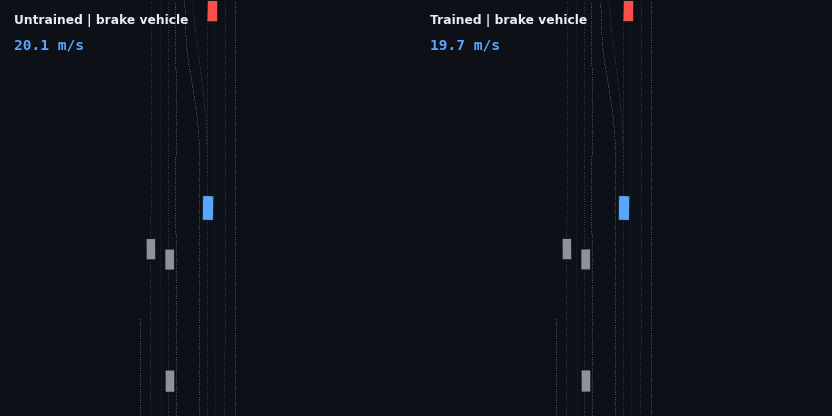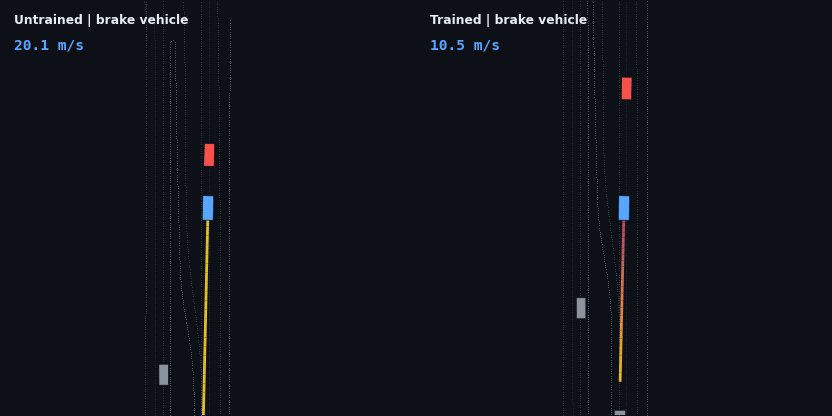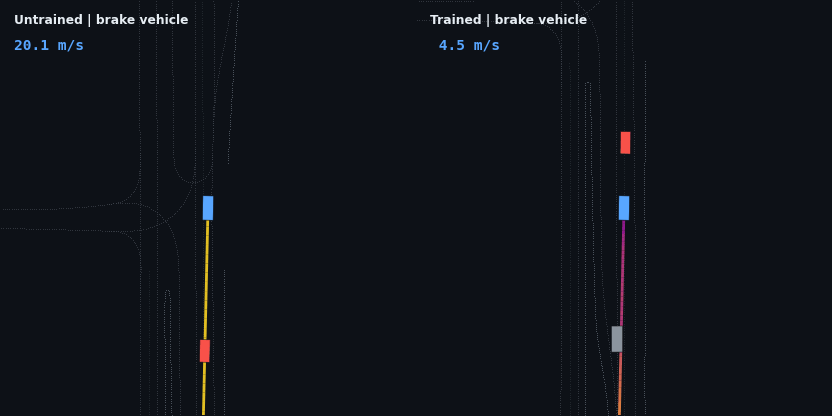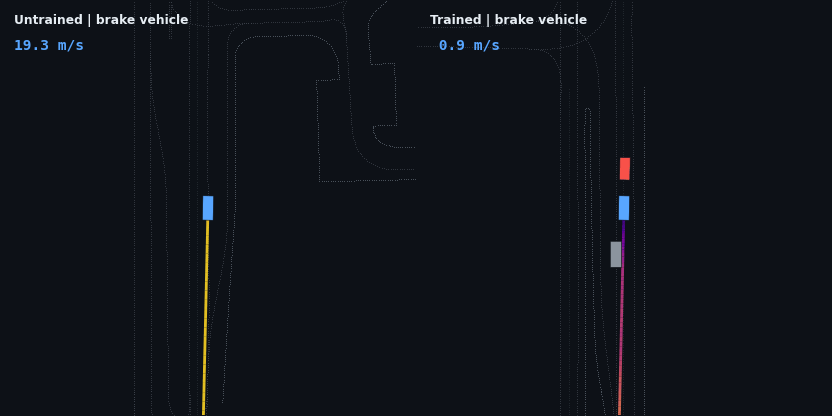
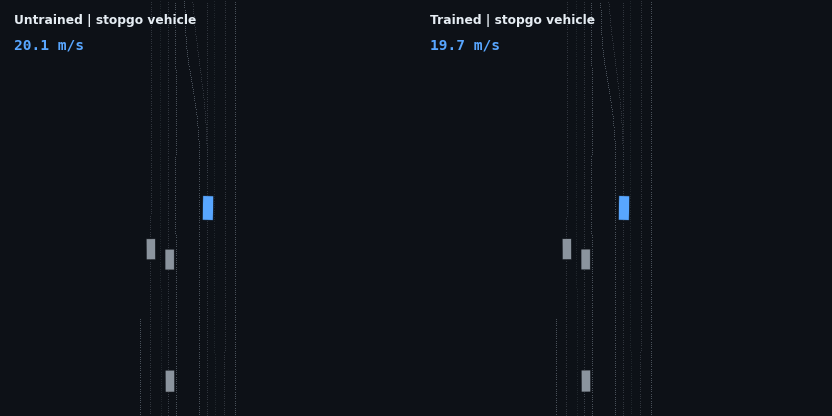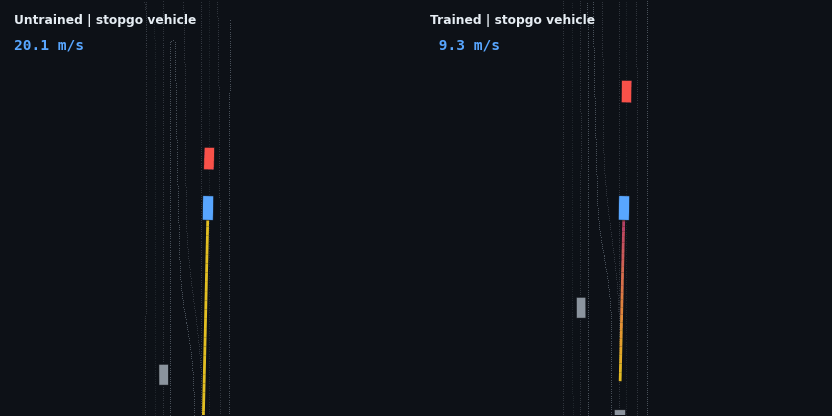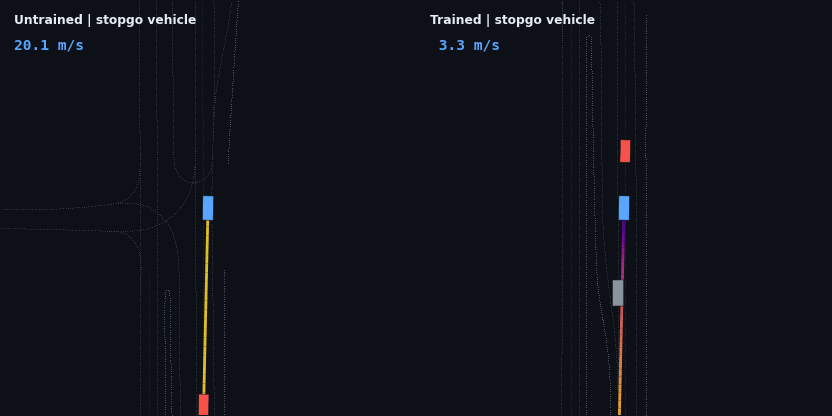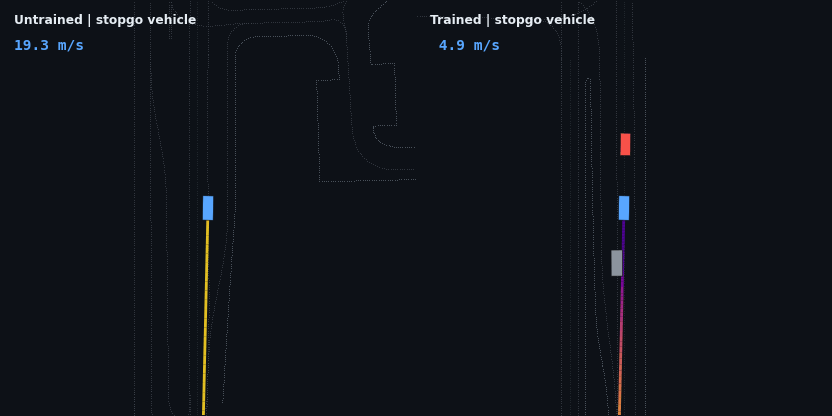
These four are adaptive cruise control working as designed: brake off the 20 m/s start, close the gap, hold the lead’s speed at a stable following distance, and — in the stop-and-go case — resume when the road clears. None of that is scripted; it is the optimum of the reward described below.
The fifth scenario is the one the policy fails:
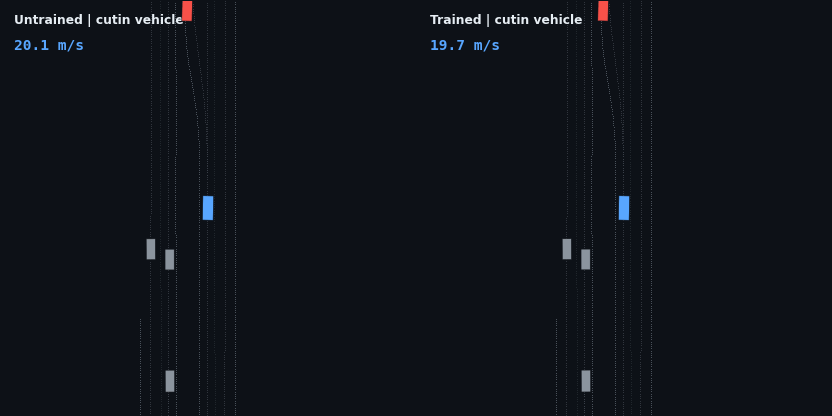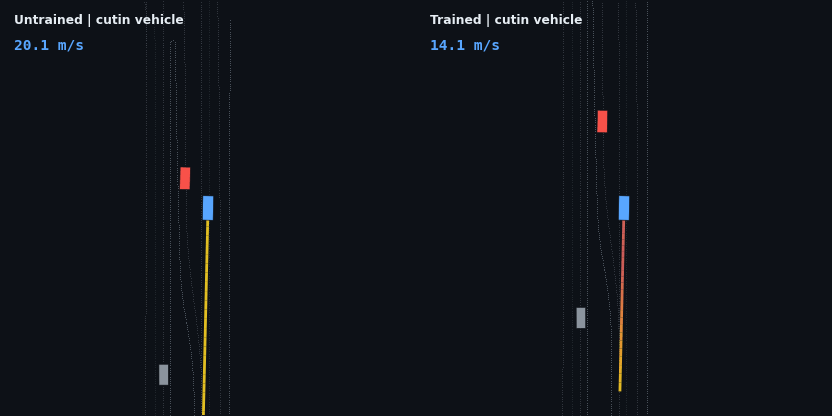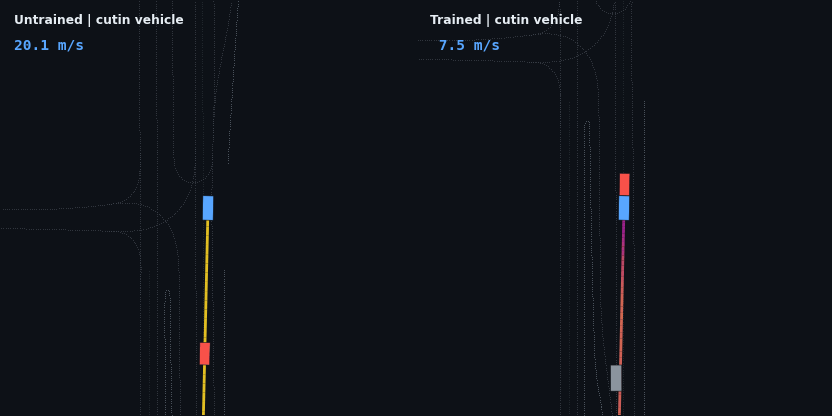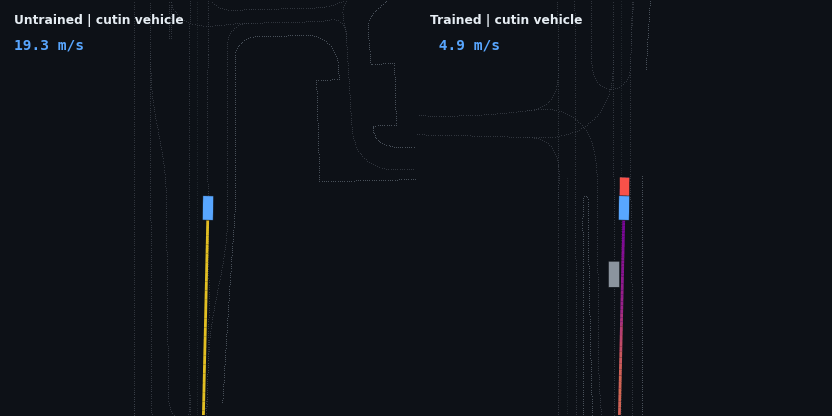
The cut-in is a genuine, measurable generalization gap. The agent reacts to the merging vehicle (it cannot see it at all until the car crosses into its ±3 m lane band, and it sheds 6 m/s within two seconds of that moment), but it stabilizes about 4 m closer than its trained following distance and clips the lead’s bounding box. The cause is the training distribution: scripted hazards always existed from the first timestep and were always in-lane, so a lead vehicle appearing at a 15 m gap mid-episode is a state the policy has never visited. The fix — randomizing hazard onset time and lateral entry during training — is mechanical; the test exists precisely to show the boundary of what the current training distribution bought.
The Waymax Simulator
Waymax is Google’s open-source, JAX-native autonomous driving simulator released at NeurIPS 2023. Unlike physics-based simulators that synthesize traffic from scratch, Waymax replays real-world scenarios from the Waymo Open Dataset (WOD): 103,354 logged driving segments, each containing the positions, velocities, headings, and object metadata of every agent observed during 9.1-second windows at 10 Hz.
Everything is JAX: the environment step, the policy forward pass, the reward (including bounding-box collision metrics), and the NPC actors JIT-compile into fused XLA programs. Measured speedup from JIT in this project: roughly 6x, bringing an 80-step episode to ~3 seconds on a laptop RTX 4070 and making the fourteen-run iteration cycle behind this page possible at 20-50 minutes per run.
| Parameter | Value |
|---|---|
| Max objects per scenario | 32 |
| Dynamics model | StateDynamics (direct state specification) |
| Controlled object | ego agent at index 2 |
| NPC behavior | IDMRoutePolicy (reactive, route-following) |
| Time step | 0.1 s |
| Episode length | 80 steps (8 s) |
| Scenario source | WOD 1.0.0 Validation split |
NPCs use Waymax’s Intelligent Driver Model route policy: logged route geometry, IDM car-following dynamics (desired speed 15 m/s, 1.5 s headway, 4 m/s² max braking). The failure catalog explains why this choice is load-bearing: with raw log replay, NPCs drive through any agent that deviates from the recorded flow, and the task becomes unsolvable.
Problem Setup
The ego starts at its logged 20.2 m/s. The task is adaptive cruise control: hold m/s on open road, track a gap-dependent safe speed behind a lead vehicle, never collide, never leave the road.
Observation (7D):
with ego speed , heading , episode progress , gap to the nearest in-lane vehicle ahead (ego body frame, capped at m), and closing speed. Every feature is there because its absence produced a documented failure: progress fixes a finite-horizon credit assignment bug, and the lead-vehicle pair is the policy’s only perception.
Actions: discrete longitudinal acceleration m/s². The asymmetry is required, not stylistic: braking at 2 m/s² needs 102 m to stop from the logged start speed, which exceeds what the scenario geometry allows; at 4 m/s² it needs 51 m. Sensing range, stopping distance, and hazard placement are mutually constrained — getting any one of them wrong made the task silently unsolvable.
Hazard randomization: every training episode pins one real vehicle to the ego’s path at a random arc distance (55-80 m) and speed (50% exactly stalled, else uniform 0-8 m/s). Without this, the IDM traffic at 15 m/s always outran the ego and the gap features carried no training signal at all.
Proximal Policy Optimization
PPO stabilizes on-policy policy gradients with a clipped ratio objective:
with GAE advantages (, ).
| Component | Specification |
|---|---|
| Policy / value networks | / |
| Clip, entropy, value coef | , , |
| Optimizers | Adam; policy , value |
| Updates | 10 epochs per episode, batch 64 |
| Final recipe | 600 episodes from scratch + 800 continued |
Reward Design
The desired speed is a constant-deceleration braking envelope — the fastest speed from which the agent can still stop short of the lead at comfortable braking :
Three properties of this design were learned the hard way (catalog entries 5, 9, 10): the envelope must be trackable by the action limits; the error scale (4 m/s, not ) must make deviations near obstacles actually expensive; and the collision penalty must be terminal — a one-time penalty that ends the episode — because any per-step overlap penalty teaches the policy to accelerate through collisions to shorten the penalized phase.
A Catalog of Failure Modes
Fourteen training runs produced ten distinct, diagnosable failures. None were visible in loss curves; every diagnosis required looking at what the agent actually did — its speed profile, its action preferences probed at fixed observations, or the geometry of its collisions. This catalog is the project’s real content.
1. The policy that controlled nothing. Reward bit-identical (383.9) across 100 episodes. create_expert_actor defaults to controlling all objects, and merge_actions gives later actors priority, so the log-replay actor silently overwrote the policy every step. A stochastic policy with zero reward variance is not acting — check that first.
2. The time-blind critic. With control fixed, the policy learned the inverse mapping (less braking at higher speed). Returns in an 80-step episode range from ~275 (step 0) to ~4 (step 79), but the observation contained nothing time-dependent, so the critic could only predict the mean and GAE advantages carried the full time trend — early actions reinforced, late ones suppressed, regardless of content. One added feature () fixed it (Pardo et al., Time Limits in RL).
3. The agent that could not see. It learned to decelerate, then collided with braking traffic ahead: the observation was a speedometer and a clock. The collision penalty could teach statistical caution but not avoidance. Fix: gap and closing speed to the in-lane lead, in the ego frame.
4. The reward hack. With perception added and a -50 per-step collision penalty, the agent accelerated to 25 m/s and outran all traffic. On-policy PPO cannot cross the penalty valley between “flee” and “follow” because every path between them passes through clumsy braking that collides. Fixed at the time with a penalty curriculum; made obsolete later by terminal collisions plus a sharper speed reward that pays fleeing ~0.
5. The infeasible reward. The first gap-speed profile, , demands of deceleration — 6 m/s² at 10 m/s against a 2 m/s² limit — and its m stopping point is inside the lead’s bounding box (centers 5 m apart of two 4.7 m cars overlap). The agent tracked it faithfully and still collided 15% of steps. The reward was demanding physics the dynamics could not deliver.
6. The simulation that made the task impossible. Collisions persisted at 15% regardless of penalty. Collision geometry showed the braking ego being hit from behind by vehicles logged at 24 m/s: log-replay NPCs are non-reactive, so any policy slower than the recorded flow gets run over. The agent’s 15% was near-optimal. Reactive IDM agents made the task well-posed — for training interactive behavior, NPC reactivity matters more than NPC fidelity.
7. The perception that never trained. With IDM traffic, training reached zero collisions and high reward — and the stress test exposed it: the policy drove straight through a stalled car. IDM traffic at 15 m/s always outran the 13.5 m/s ego, so the gap features sat at “nothing ahead” for the entire run and the network never learned to read them. Zero training collisions partly meant nothing to hit. Fix: hazard randomization, so the features carry signal.
8. The impossible curriculum. The first hazard range (40-90 m) ignored the stopping math: 102 m needed from the start speed at the then-2 m/s² braking limit, with a 50 m sensing cap that hid the hazard until past the brake-now point. Most training episodes were unavoidable crashes, and the learner was being punished for physics. A curriculum is only a curriculum if the task is solvable.
9. The horizon exploit. With feasible kinematics (4 m/s² braking, 80 m sensing, hazards 60-140 m), training showed near-zero collisions but the stress test still failed: the agent braked to ~9 m/s and crept into the stalled car. Hazards beyond ~90 m are never reached within an 80-step episode, so “brake to 9 and run out the clock” was indistinguishable from “stop” in most of the training data. Fix: place hazards where the encounter must happen with episode time to spare.
10. Accelerating through the crash. The subtlest one. With everything else fixed, probing the policy revealed P(accelerate) = 0.94 at 9 m/s and 9 m gap — it had learned to floor it through the obstacle. Under a per-step overlap penalty, once too close to stop, higher speed means fewer steps in contact and a higher return. Punching through was genuinely optimal. Fix: terminal collision semantics (one-time -200, episode over), which forfeits all future reward and makes early crashes strictly worse than late ones.
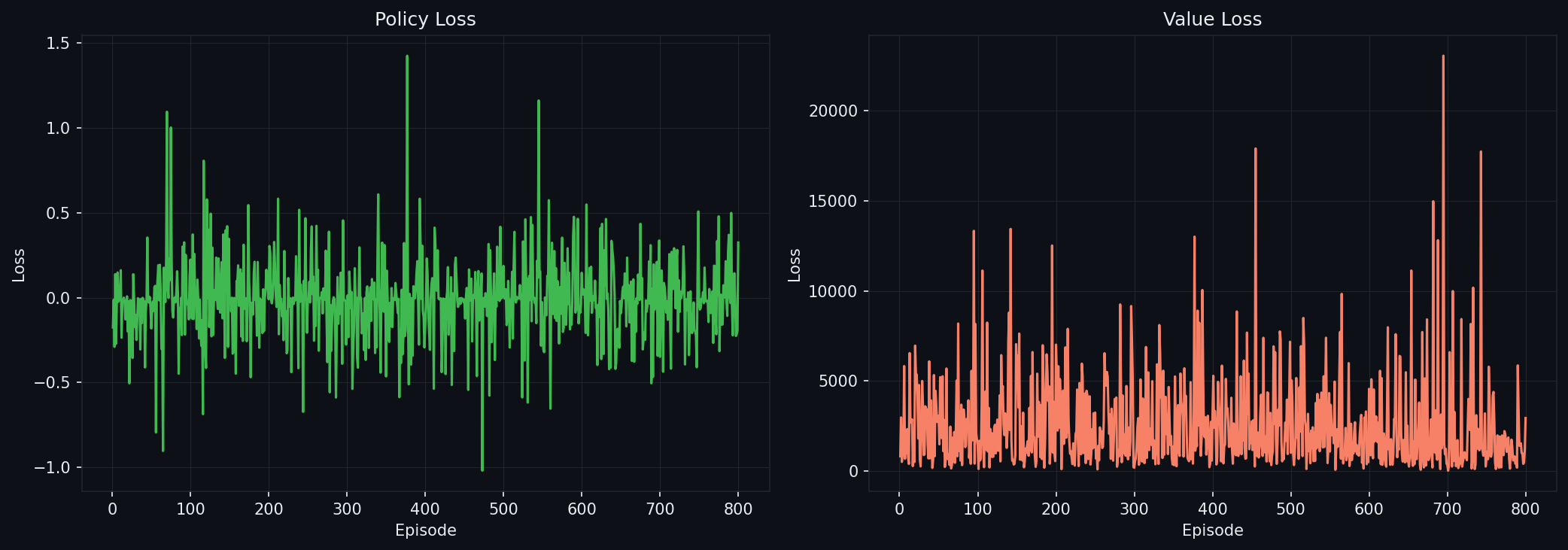
Training Results
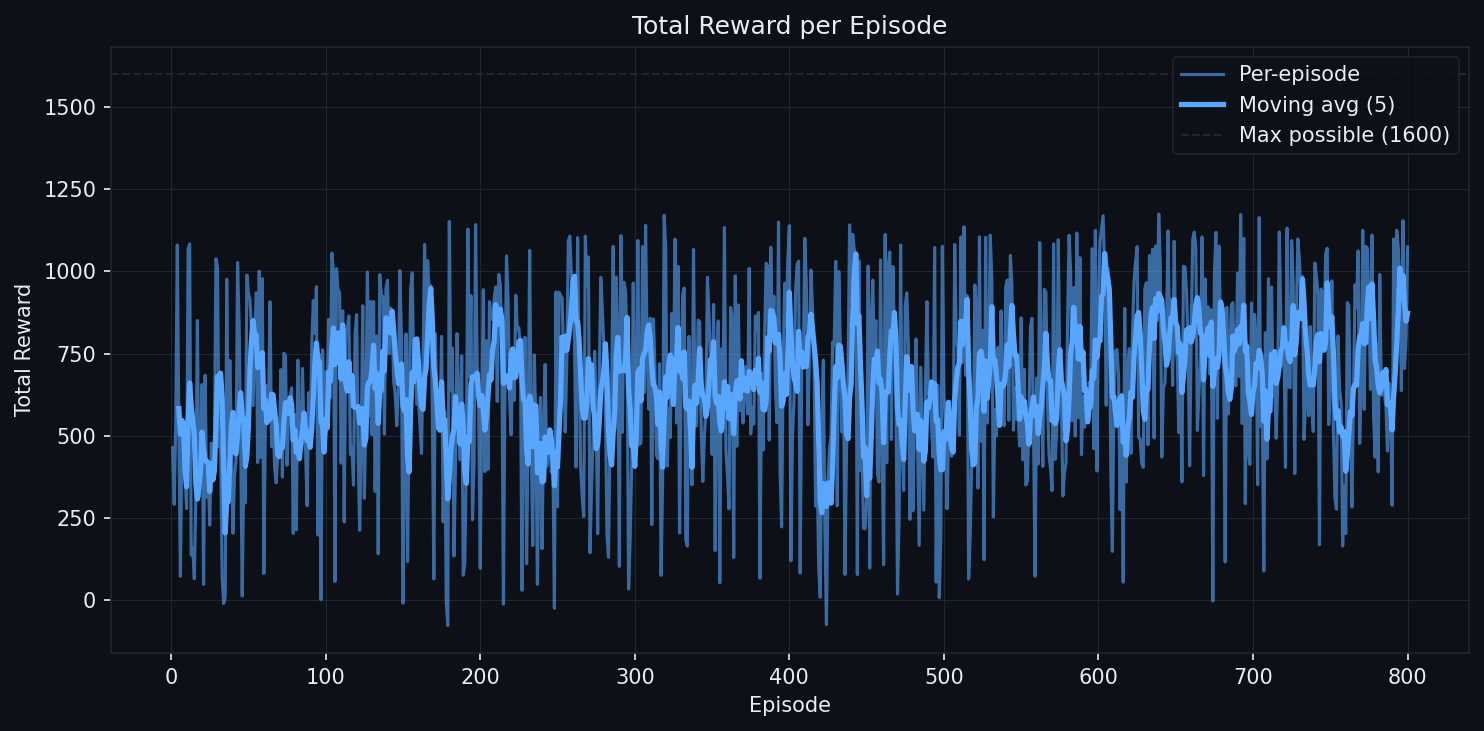
The final recipe (terminal collisions, stall-biased hazards, braking envelope, 7D observation) trains from scratch in 600 episodes and continues for 800 more, ending at a 941 final-10 average reward with collision-terminated episodes nearly eliminated (under 1% of steps in the last 200 episodes, where every episode contains a guaranteed hazard encounter).
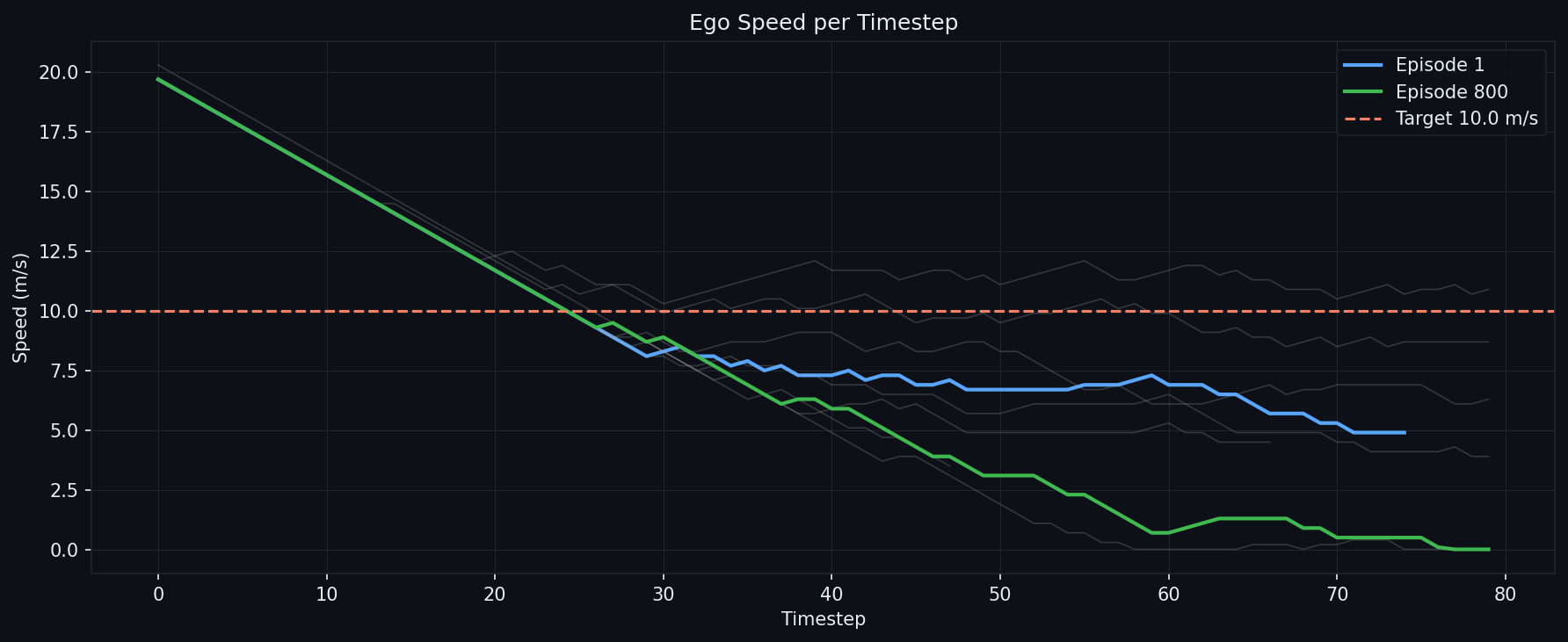
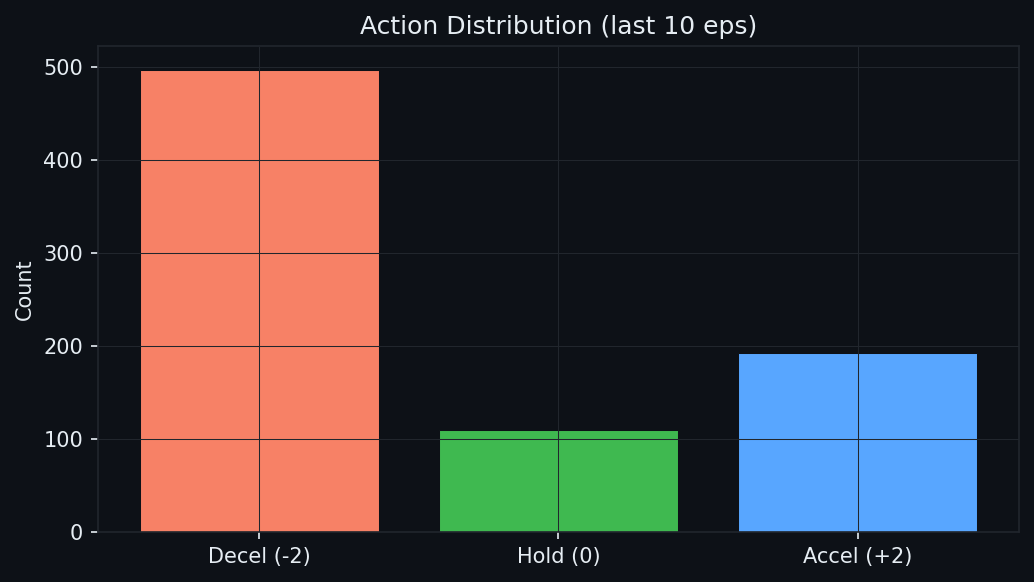
The learned control law, probed directly at fixed observations, uses perception the way a cruise controller should — same speed, opposite actions depending on what is ahead:
| Ego speed | Gap | Closing | P(brake) | P(hold) | P(accel) |
|---|---|---|---|---|---|
| 10 m/s | 80 m (open road) | 0 | 0.01 | 0.15 | 0.84 |
| 10 m/s | 30 m | 10 m/s | 0.91 | 0.02 | 0.06 |
| 9 m/s | 20 m | 9 m/s | 0.88 | 0.03 | 0.09 |
| 6 m/s | 12 m | 6 m/s | 0.76 | 0.11 | 0.14 |
| 3 m/s | 9 m | 3 m/s | 0.43 | 0.37 | 0.20 |
| 1 m/s | 9 m | 1 m/s | 0.21 | 0.61 | 0.19 |
Hard braking at speed when closing on an obstacle, easing off as the gap-speed envelope is satisfied, settling to hold near standstill. The earlier generations of this policy showed flat or inverted gap responses at these same probe points.
Discussion
Four durable lessons, each paid for with a failed training run:
Behavioral evaluation is the only evaluation. Loss curves looked healthy through all ten failures. Reward curves looked excellent through three of them (7, 9, 10) — high reward, near-zero training collisions, and a policy that drove through parked cars when tested. The tools that actually localized faults: bit-exact reward comparison, speed profiles, collision geometry (who hit whom, from where), and probing action probabilities on a grid of synthetic observations.
Every component of the MDP can silently invalidate the task. The observation (no time feature, no perception), the action space (symmetric braking), the reward (infeasible envelope, per-step collision penalty), the horizon (unreachable hazards), and the simulator itself (non-reactive NPCs) each independently made the stated task unlearnable or a different task than intended. RL debugging is mostly task debugging.
Incentives at the margin decide behavior. The punch-through policy (failure 10) was not a learning artifact — it was the correct optimum of the written reward, discovered reliably. The fix was not more training but changing the marginal economics: terminal collision semantics make every step of avoided contact worth its full future reward.
Stress tests find what training metrics cannot. Run 8 was, by every training metric, a success. Injecting a parked car — a 20-line counterfactual edit of the scenario — exposed that its perception had never trained. The five-scenario suite is now the project’s acceptance criteria: the final policy passes four with zero contact, and the fifth (cut-in) localizes the exact boundary of the training distribution — hazards that appear mid-episode at small gap — instead of leaving it unknown.
Two limitations remain, both with mechanical fixes. The cut-in gap closes by randomizing hazard onset time and lateral entry during training, the same hazard machinery that produced the other behaviors. Map diversity is gated on data access: Waymax’s only data source is the Waymo Open Motion Dataset, so new road geometries mean new WOMD scenarios rather than synthetic generation. The infrastructure — JIT-compiled episodes, scripted hazard actors, the stress-test harness — is built to scale to both.
Related projects
Deep Learning from Scratch
The full arc: backpropagation in raw NumPy, CNNs with BatchNorm and Dropout trained to 78% on CIFAR-10, multi-head self-attention for text summarization, and a Masked Autoencoder that reconstructs images from 25% of their patches, then transfers those features to downstream tasks.
Classical ML from Scratch
Two learning paradigms built from NumPy up: tree-based spam classification (decision tree, Random Forest, AdaBoost) and SVD/ALS matrix factorization for movie recommendations. No frameworks; matched scikit-learn on both.

Entropy Wordle Solver
Information-theoretic greedy solver that picks each guess to maximize expected entropy over the remaining word set, averaging 3.92 guesses across 300+ games.